# 扩展和集成
# 1.Spring
# 1.1.Spring Boot
# 1.1.1.概述
Spring Boot是一个广泛使用的Java框架,它使开发基于Spring的独立应用变得非常容易。
Ignite提供了2个扩展来完成Spring Boot环境的自动化配置:
ignite-spring-boot-autoconfigure-ext:在Spring Boot中自动化配置Ignite的服务端和客户端节点;ignite-spring-boot-thin-client-autoconfigure-ext:在Spring Boot中自动化配置Ignite的瘦客户端节点。
# 1.1.2.自动化配置Ignite的服务端和客户端
需要使用ignite-spring-boot-autoconfigure-ext扩展来使用Spring Boot自动化配置Ignite的服务端和客户端(胖客户端)。
通过Maven添加扩展的方式如下:
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-spring-boot-autoconfigure-ext</artifactId>
<version>1.0.0</version>
</dependency>
添加之后,Spring在启动之后会自动创建一个Ignite实例。
# 1.1.2.1.通过Spring Boot的配置文件配置Ignite
可以使用常规的Spring Boot配置文件对Ignite进行配置,前缀是ignite:
ignite:
igniteInstanceName: properties-instance-name
communicationSpi:
localPort: 5555
dataStorageConfiguration:
defaultDataRegionConfiguration:
initialSize: 10485760 #10MB
dataRegionConfigurations:
- name: my-dataregion
initialSize: 104857600 #100MB
cacheConfiguration:
- name: accounts
queryEntities:
- tableName: ACCOUNTS
keyFieldName: ID
keyType: java.lang.Long
valueType: java.lang.Object
fields:
ID: java.lang.Long
amount: java.lang.Double
updateDate: java.util.Date
- name: my-cache2
# 1.1.2.2.通过编程的方式配置Ignite
有两种编程方式:
创建
IgniteConfigurationBean: 只需要创建一个方法返回IgniteConfiguration即可,其会通过开发者的配置创建Ignite实例:@Bean public IgniteConfiguration igniteConfiguration() { // If you provide a whole ClientConfiguration bean then configuration properties will not be used. IgniteConfiguration cfg = new IgniteConfiguration(); cfg.setIgniteInstanceName("my-ignite"); return cfg; }通过Spring Boot配置自定义
IgniteConfiguration: 如果希望自定义通过Spring Boot配置文件创建的IgniteConfiguration,那么需要在应用的上下文中提供一个IgniteConfigurer的实现。首先,
IgniteConfiguration会被Spring Boot加载,然后其实例会被传入配置器:@Bean public IgniteConfigurer nodeConfigurer() { return cfg -> { //Setting some property. //Other will come from `application.yml` cfg.setIgniteInstanceName("my-ignite"); }; }
# 1.1.3.自动化配置Ignite的瘦客户端
需要使用ignite-spring-boot-thin-client-autoconfigure-ext扩展来自动化配置Ignite的瘦客户端。
通过Maven添加扩展的方式如下:
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-spring-boot-thin-client-autoconfigure-ext</artifactId>
<version>1.0.0</version>
</dependency>
添加之后,Spring在启动之后会自动创建一个Ignite的瘦客户端连接实例。
# 1.1.3.1.通过Spring Boot的配置文件配置瘦客户端
可以使用常规的Spring Boot配置文件对IgniteClient进行配置,前缀是ignite-client:
ignite-client:
addresses: 127.0.0.1:10800 # this is mandatory property!
timeout: 10000
tcpNoDelay: false
# 1.1.3.2.通过编程的方式配置瘦客户端
有两种编程方式配置IgniteClient对象:
创建
ClientConfigurationBean: 只需要创建一个方法返回ClientConfiguration即可,其会通过开发者的配置创建IgniteClient实例:@Bean public ClientConfiguration clientConfiguration() { // If you provide a whole ClientConfiguration bean then configuration properties will not be used. ClientConfiguration cfg = new ClientConfiguration(); cfg.setAddresses("127.0.0.1:10800"); return cfg; }通过Spring Boot配置自定义
ClientConfiguration: 如果希望自定义通过Spring Boot配置文件创建的ClientConfiguration,那么需要在应用的上下文中提供一个IgniteClientConfigurer的实现。首先,
ClientConfiguration会被Spring Boot加载,然后其实例会被传入配置器:@Bean IgniteClientConfigurer configurer() { //Setting some property. //Other will come from `application.yml` return cfg -> cfg.setSendBufferSize(64*1024); }
# 1.1.4.示例
这里有若干示例供参考。
# 1.2.Spring Data
# 1.2.1.概述
Spring Data框架提供了一套统一并且广泛使用的API,它从应用层抽象了底层的数据存储,Spring Data有助于避免锁定到某数据库厂商,通过很小的代价就可以从一个数据库切换到另一个,Ignite通过实现CrudRepository接口来与Spring Data集成。
# 1.2.2.Maven配置
开始使用Ignite的Spring Data库的最简单方式就是将下面的Maven依赖加入应用的pom.xml文件:
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-spring-data-ext</artifactId>
<version>${ignite-spring-data-ext.version}</version>
</dependency>
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-core</artifactId>
<version>${ignite.version}</version>
</dependency>
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-indexing</artifactId>
<version>${ignite.version}</version>
</dependency>
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-spring</artifactId>
<version>${ignite.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-commons</artifactId>
<version>${spring.data.version}</version>
</dependency>
将${ignite-spring-data-ext.version}、${spring.data.version}和${ignite.version}分别替换为实际使用的版本。
下表列出了可用的Ignite Spring Data扩展版本及其对应的兼容Ignite版本:
| Ignite Spring Data扩展版本 | 兼容Ignite版本 |
|---|---|
| 1.0.0 | 2.8.0及以后 |
| 2.0.0 | 2.8.0及以后 |
注意
如果使用的Spring Data版本低于Spring Data 2.2,那么需要在pom.xml中将artifactId配置为ignite-spring-data-2.0-ext或者ignite-spring-data-ext。
# 1.2.3.IgniteRepository
Ignite引入了一个专门的IgniteRepository接口,扩展了默认的CrudRepository,这个接口可以被所有希望从Ignite集群中存储和查询数据的自定义Spring Data Repository继承。
比如,创建一个名为PersonRepository的自定义Repository:
@RepositoryConfig(cacheName = "PersonCache")
public interface PersonRepository extends IgniteRepository<Person, Long> {
/**
* Gets all the persons with the given name.
* @param name Person name.
* @return A list of Persons with the given first name.
*/
public List<Person> findByFirstName(String name);
/**
* Returns top Person with the specified surname.
* @param name Person surname.
* @return Person that satisfy the query.
*/
public Cache.Entry<Long, Person> findTopByLastNameLike(String name);
/**
* Getting ids of all the Person satisfying the custom query from {@link Query} annotation.
*
* @param orgId Query parameter.
* @param pageable Pageable interface.
* @return A list of Persons' ids.
*/
@Query("SELECT id FROM Person WHERE orgId > ?")
public List<Long> selectId(long orgId, Pageable pageable);
}
@RepositoryConfig注解需要指定,它会将Repository映射到一个分布式缓存,在上面的示例中,PersonRepository映射到了PersonCache;- 自定义方法(比如
findByFirstName(name)以及findTopByLastNameLike(name))的签名会被自动处理,在该方法被调用时会被转成对应的SQL查询。另外,如果需要执行明确的SQL查询作为方法调用的结果,也可以使用@Query(queryString)注解。
不支持的CRUD操作
CrudRepository接口的部分操作目前还不支持。这些操作是不需要提供主键作为参数的:
save(S entity)save(Iterable<S> entities)delete(T entity)delete(Iterable<? extends T> entities)
这些操作可以使用IgniteRepository接口中提供的功能相当的函数替代:
save(ID key, S entity)save(Map<ID, S> entities)deleteAll(Iterable<ID> ids)
# 1.2.4.Spring Data和Ignite配置
Ignite的Spring Data集成支持通过胖客户端或者瘦客户端接入集群,这两种接入集群的方式都使用相同的API,如下所示,Ignite的Spring Data集成会自动识别注入的Bean的类型,然后使用正确的集群连接。
要在Spring Data中启用面向Ignite的Repository,需要在应用的配置上添加@EnableIgniteRepositories注解,如下所示:
这个配置会实例化传入IgniteRepositoryFactoryBean的胖客户端/瘦客户端Bean,然后用于所有需要接入Ignite集群的Ignite Repository。
在上例中,应用会直接实例化该bean,然后命名为igniteInstance,另外,配置也可以注册下面的bean,然后自动地启动一个Ignite节点。
- 名为
igniteCfg的IgniteConfiguration对象; - 名为
igniteSpringCfgPath的指向Ignite的Spring XML配置文件的路径。
对于使用瘦客户端接入集群的场景,则需要注册名为igniteCfg的ClientConfigurationBean,这样Ignite的Spring Data集成就会自动启动瘦客户端实例。
# 1.2.5.使用IgniteRepository
所有的配置和Repository准备好之后,就可以在应用的上下文中注册配置以及获取Repository的引用。下面的示例代码就会展示如何在应用的上下文中注册SpringAppCfg(上面章节的示例配置),然后获取PersonRepository的引用:
ctx = new AnnotationConfigApplicationContext();
// Explicitly registering Spring configuration.
ctx.register(SpringAppCfg.class);
ctx.refresh();
// Getting a reference to PersonRepository.
repo = ctx.getBean(PersonRepository.class);
下面,就可以使用Spring Data的API将数据加入分布式缓存:
TreeMap<Long, Person> persons = new TreeMap<>();
persons.put(1L, new Person(1L, 2000L, "John", "Smith", 15000, "Worked for Apple"));
persons.put(2L, new Person(2L, 2000L, "Brad", "Pitt", 16000, "Worked for Oracle"));
persons.put(3L, new Person(3L, 1000L, "Mark", "Tomson", 10000, "Worked for Sun"));
// Adding data into the repository.
repo.save(persons);
如果要查询数据,可以使用基本的CRUD操作或者方法,它们会自动地转换为Ignite的SQL查询。
List<Person> persons = repo.findByFirstName("John");
for (Person person: persons)
System.out.println(" >>> " + person);
Cache.Entry<Long, Person> topPerson = repo.findTopByLastNameLike("Smith");
System.out.println("\n>>> Top Person with surname 'Smith': " +
topPerson.getValue());
# 1.2.6.示例
GitHub上有完整的示例。
# 1.3.Spring缓存
# 1.3.1.概述
Spring缓存抽象提供了一种基于注释的方式来启用Java方法的缓存,以便将方法执行的结果存储在外部缓存存储中。之后如果使用相同的参数集调用同一方法,则将从缓存中检索结果,而不是实际执行该方法。
Apache Ignite提供了ignite-spring-cache-ext扩展,可以将Ignite的缓存作为Spring缓存抽象的外部存储。上述集成是通过提供SpringCacheManager接口的实现来实现的。有两个这样的实现:SpringCacheManager和IgniteClientSpringCacheManager,它们使用Ignite的胖/瘦客户端接入Ignite集群并执行数据缓存。
# 1.3.2.Maven配置
如果项目中使用Maven来管理依赖,可以像下面这样,将Ignite的Spring缓存扩展依赖加入应用的pom.xml文件中:
分别将${ignite-spring-cache-ext.version}、${spring.version}和${ignite.version}替换为实际使用的版本号。
下表显示了Ignite的Spring缓存扩展的可用版本以及和Ignite及Spring的兼容性。
| Ignite的Spring缓存扩展版本 | Ignite版本 | Spring版本 |
|---|---|---|
| 1.0.0 | 2.11.0及以后 | 4.3.0及以后 |
# 1.3.3.Ignite胖客户端缓存管理器配置
# 1.3.3.1.集群接入配置
要将Ignite缓存嵌入使用Ignite胖客户端接入Ignite集群的Spring应用,只需执行两个简单的步骤即可:
- 以嵌入式模式(即在运行应用的同一JVM中)以适当的配置启动Ignite胖客户端。可以有预定义的缓存,但这不是必需的 - 如果需要,缓存将在第一次访问时自动创建;
- 在Spring应用上下文中将
SpringCacheManager配置为缓存管理器。
SpringCacheManager可以自行启动嵌入式胖客户端。这时需要通过configurationPath属性提供Ignite的XML配置文件的路径,或通过configuration属性提供IgniteConfiguration实例(参见下面的示例)。注意同时设置这两个参数是非法的,会导致IllegalArgumentException。
指定Ignite的胖客户端配置:
指定Ignite的XML配置文件路径:
手工指定已启动的Ignite节点实例名:
当缓存管理器初始化时(例如它是使用ServletContextListenerStartup启动的),可能已经有一个Ignite节点实例在运行。这时简单地通过igniteInstanceName属性提供Ignite节点实例名即可。注意如果未指定实例名,缓存管理器将尝试使用默认的Ignite实例(实例名为null),下面是一个示例:
提示
在应用内部启动的节点是接入整个拓扑的入口点。可以按需启动任意数量的远程独立节点,所有这些节点都将参与缓存数据。
# 1.3.3.2.动态缓存
虽然通过Ignite配置文件可以获得所有必要的缓存,但是这不是必要的。如果Spring要使用一个不存在的缓存时,SpringCacheManager会自动创建它。
如果不指定,会使用默认配置创建一个新的缓存。也可以通过dynamicCacheConfiguration属性提供一个配置模板进行自定义,比如,如果希望使用REPLICATED缓存而不是PARTITIONED缓存,可以像下面这样配置SpringCacheManager:
也可以在客户端侧使用近缓存,只需要简单地通过dynamicNearCacheConfiguration属性提供一个近缓存配置即可。近缓存默认是不启用的,下面是一个示例:
# 1.3.4.Ignite瘦客户端缓存管理器配置
本章节会展示如何配置IgniteClientSpringCacheManager,它是依赖瘦客户端接入Ignite集群并执行缓存。
警告
IgniteClientSpringCacheManager不支持Spring缓存同步模式(Cacheable#sync)。如果此功能对业务至关重要,只能用SpringCacheManager,它是使用Ignite胖客户端接入Ignite集群的。
# 1.3.4.1.集群接入配置
集群连接配置定义了接入集群的IgniteClientSpringCacheManager使用的Ignite瘦客户端,具体有几种方式:
提示
混合使用多种方法是不正确的 - 这会导致管理器启动期间出现IllegalArgumentException异常。
指定Ignite瘦客户端实例:
指定Ignite瘦客户端配置:
这时IgniteClientSpringCacheManager会根据提供的配置,自动启动瘦客户端实例:
# 1.3.4.2.动态缓存
IgniteClientSpringCacheManager的动态缓存配置,与SpringCacheManager使用Ignite节点实例访问集群的执行方式相同。
# 1.3.5.示例
如果在Spring应用上下文中已经加入了SpringCacheManager,就可以通过简单地加上注解为任意的java方法启用缓存。
通常为很重的操作使用缓存,比如数据库访问。比如,假设有个Dao类有一个averageSalary(...)方法,它计算一个组织内的所有雇员的平均工资,那么可以通过@Cacheable注解来开启这个方法的缓存。
private JdbcTemplate jdbc;
@Cacheable("averageSalary")
public long averageSalary(int organizationId) {
String sql =
"SELECT AVG(e.salary) " +
"FROM Employee e " +
"WHERE e.organizationId = ?";
return jdbc.queryForObject(sql, Long.class, organizationId);
}
当这个方法第一次被调用时,SpringCacheManager会自动创建一个averageSalary缓存,它也会在缓存中查找事先计算好的平均值然后如果存在,就会直接返回,如果这个组织的平均值还没有被计算过,那么这个方法就会被调用然后将结果保存在缓存中,因此下一次请求这个组织的平均值,就不需要访问数据库了。
如果一个雇员的工资发生变化,可能希望从缓存中删除这个雇员所属组织的平均值,否则averageSalary(...)方法会返回过时的缓存结果。这个可以通过将@CacheEvict注解加到一个方法上来更新雇员的工资:
private JdbcTemplate jdbc;
@CacheEvict(value = "averageSalary", key = "#e.organizationId")
public void updateSalary(Employee e) {
String sql =
"UPDATE Employee " +
"SET salary = ? " +
"WHERE id = ?";
jdbc.update(sql, e.getSalary(), e.getId());
}
在这个方法被调用之后,该雇员所属组织的平均值就会被从averageSalary缓存中踢出,这会强迫averageSalary(...)方法在下次调用时重新计算。
Spring表达式语言(SpEL)
注意这个方法是以雇员为参数的,而平均值是通过organizationID将平均值存储在缓存中的。为了明确地指定什么作为缓存键,可以使用注解的key参数和Spring表达式语言。
#e.organizationId表达式的意思是从e变量中获取organizationId属性的值。本质上会在提供的雇员对象上调用getOrganizationId()方法,以及将返回的值作为缓存键。
# 1.4.Spring事务
# 1.4.1.概述
Spring的事务抽象可以使开发者使用声明式事务管理,这样就可以专注于业务逻辑而不是事务生命周期。
Ignite提供了ignite-spring-tx-ext扩展,可以通过Spring事务抽象来管理Ignite事务。该扩展是通过提供Spring事务接口的TransactionManager实现来实现的,具体为两个:SpringTransactionManager和IgniteClientSpringTransactionManager,它们分别使用Ignite的原生客户端或瘦客户端接入Ignite集群并管理Ignite事务。
为了在Spring应用中启用声明式事务管理,需要在Spring的应用上下文中创建和配置SpringTransactionManager或IgniteClientSpringTransactionManagerbean,具体的选择取决于访问Ignite集群的方式。
# 1.4.2.Maven配置
如果使用Maven管理项目中的依赖,可以将Spring事务扩展依赖添加到应用的pom.xml文件中,如下所示:
分别将${ignite-spring-tx-ext.version}、${spring.version}和${ignite.version}替换为实际使用的版本号。
下表显示了可用的Ignite Spring事务扩展版本及其与Ignite版本和Spring版本的兼容性:
| Ignite Spring事务扩展版本 | Ignite版本 | Spring版本 |
|---|---|---|
| 1.0.0 | 2.11.0及之后的版本 | 4.3.0及之后的版本 |
# 1.4.3.胖客户端事务管理器配置
本章演示在使用原生客户端接入集群时,如何配置SpringTransactionManager并管理事务。配置包括两步:接入集群配置和事务并发模型配置。
# 1.4.3.1.接入集群配置
接入集群配置定义了SpringTransactionManager用于接入集群的Ignite节点,可以使用以下方法。
提示
多种方式混用是不正确的,会导致事务管理器启动时抛出异常。
指定启动的的Ignite节点实例名: 该方法适用于应用中已经有运行的Ignite节点的场景:
指定Ignite节点配置: 该方法事务管理器会根据提供的配置自动启动一个Ignite节点:
指定Ignite节点配置文件路径: 该方法事务管理器会根据提供的配置自动启动一个Ignite节点:
提示
如果未指定接入配置,SpringTransactionManager会使用默认名字的Ignite节点实例,如果不存在,SpringTransactionManager启动时会抛出异常。
警告
无论选择哪种配置方法,都必须使用相同的Ignite节点实例来初始化事务管理器并执行事务操作。如果Ignite节点是由事务管理器启动的,在应用中可以通过Ignition.ignite("<name of the Apache Ignite node instance>");来获得该实例。
# 1.4.3.2.事务并发模型配置
事务并发模型配置定义了事务管理器将应用于其处理的所有事务的Ignite事务并发模型。
提示
如果未配置事务并发模型,则会使用PESSIMISTIC并发模型。
如果应用中需要支持多个事务并发模型,则需要为每个并发模型配置对应的事务管理器,然后在处理每个事务时分别指定要使用的事务管理器:
public class TransactionalService {
@Transactional("optimisticTransactionManager")
public void doOptimistically() {
// Method body.
}
@Transactional("pessimisticTransactionManager")
public void doPessimistically() {
// Method body.
}
}
# 1.4.4.瘦客户端事务管理器配置
本章演示在使用瘦客户端接入集群时,如何配置IgniteClientSpringTransactionManager并管理事务。
# 1.4.4.1.接入集群配置
接入集群配置定义了IgniteClientSpringTransactionManager用于接入集群的Ignite瘦客户端实例。
警告
必须使用相同的Ignite瘦客户端实例来初始化事务管理器并执行事务操作。
# 1.4.4.2.事务并发模型配置
IgniteClientSpringTransactionManager的事务并发模型配置与SpringTransactionManager相同。
# 1.4.5.示例
Spring事务集成方面的示例,可以参见GitHub上的代码。
# 2.Ignite和Spark
# 2.1.概述
Ignite作为一个分布式的内存数据库,对于Spark用户可以实现如下的功能:
- 获得真正的可扩展的内存级性能,避免数据源和Spark工作节点和应用之间的数据移动;
- 提升DataFrame和SQL的性能;
- 在Spark作业之间更容易地共享状态和数据。
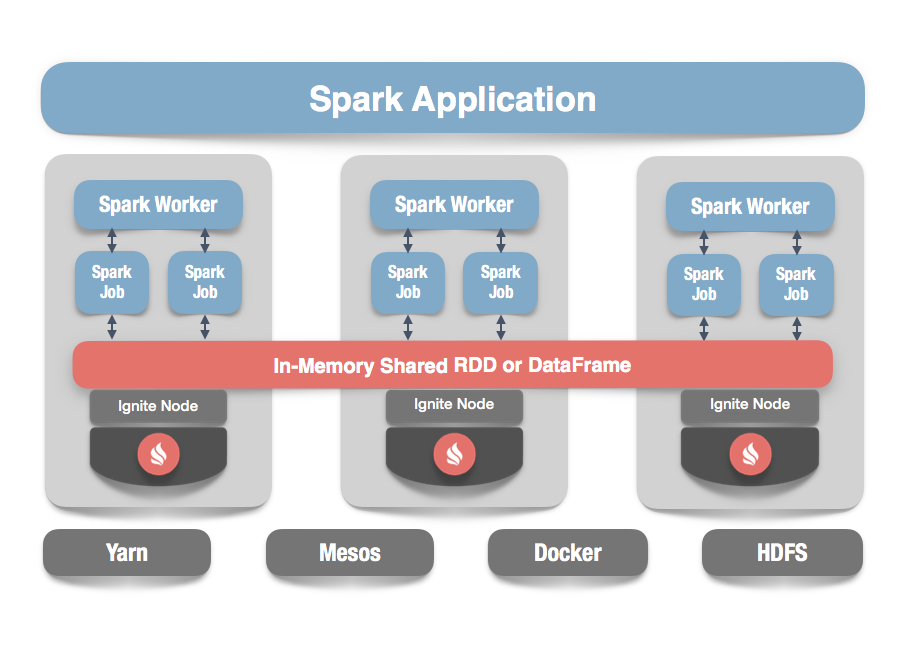
# 2.1.1.IgniteRDD
Ignite提供了一个Spark RDD抽象的实现,它可以容易地在内存中跨越多个Spark作业共享状态,在跨越不同Spark作业、工作节点或者应用时,IgniteRDD为内存中的相同数据提供了一个共享的、可变的视图,而原生的SparkRDD无法在Spark作业或者应用之间进行共享。
IgniteRDD实现的方式是作为一个分布式的Ignite缓存(或者表)的视图,它可以作为一个节点部署在Spark执行进程内部,或者Spark 工作节点上或者它自己的集群中。这意味着根据选择的不同的部署模型,共享状态可能只存在于一个Spark应用的生命周期内(嵌入式模式),或者可能存在于Spark应用外部(独立模式),这时状态可以在多个Spark应用之间共享。
虽然SparkSQL支持丰富的SQL语法,但是它没有实现索引。从结果上来说,即使在普通的较小的数据集上,Spark查询也可能花费几分钟的时间,因为需要进行全表扫描。如果使用Ignite,Spark用户可以配置主索引和二级索引,这样可以带来上千倍的性能提升。
# 2.1.2.Ignite DataFrames
Spark DataFrame API引入了描述数据的模式的概念,这样Ignite就可以管理模式并且将数据组织成表格的形式。简单来说,DataFrame就是一个将数据组织成命名列的分布式集合,它在概念上等价于关系数据库中的表,Spark会利用催化剂查询优化器的优势,生成一个比RDD更高效的查询执行计划,而RDD只是一个集群范围的、分区化的元素的集合。
Ignite扩展了DataFrame,简化了开发,并且如果Ignite用作Spark的内存存储,还会改进数据访问的时间,好处包括:
- 通过在Ignite中读写DataFrame,可以在Spark作业间共享数据和状态;
- 使用Ignite的SQL引擎,包括高级索引以及避免Ignite和Spark之间的网络数据移动,可以优化Spark的查询执行计划,从而实现更快的SparkSQL查询。
# 2.1.3.支持的Spark版本
Ignite有两个模块,分别支持不同的Spark版本:
ignite-spark-ext 1.0.0:与Spark2.3版本集成;ignite-spark-ext 2.0.0:与Spark2.4版本集成。
# 2.2.IgniteContext和IgniteRDD
# 2.2.1.IgniteContext
IgniteContext是Spark和Ignite集成的主要入口点。要创建一个Ignite上下文的实例,必须提供一个SparkContext的实例以及创建IgniteConfiguration的闭包(配置工厂)。Ignite上下文会确保Ignite服务端或者客户端节点存在于所有参与的作业实例中。或者,一个XML配置文件的路径也可以传入IgniteContext构造器,它会用于配置启动的节点。
当创建一个IgniteContext实例时,一个可选的booleanclient参数(默认为true)可以传入上下文构造器,这个通常用于一个共享部署安装,当client设为false时,上下文会操作于嵌入式模式然后在上下文创建期间在所有的工作节点上启动服务端节点。可以参照安装与部署章节了解有关部署配置的信息。
嵌入式模式已被废弃
嵌入式模式意味着需要在Spark执行器中启动Ignite服务端节点,这可能导致意外的再平衡甚至数据丢失,因此该模式目前已被弃用并且最终会被废弃。可以考虑启动一个单独的Ignite集群然后使用独立模式来避免数据的一致性和性能问题。
一旦创建了IgniteContext,IgniteRDD的实例可以通过fromCache方法获得,当RDD创建之后请求的缓存在Ignite集群中是否存在不是必要的,如果指定名字的缓存不存在,会用提供的配置或者模板配置创建它。
比如,下面的代码会用默认的Ignite配置创建一个Ignite上下文:
val igniteContext = new IgniteContext(sparkContext,
() => new IgniteConfiguration())
下面的代码会从example-shared-rdd.xml的配置创建一个Ignite上下文:
val igniteContext = new IgniteContext(sparkContext,
"examples/config/spark/example-shared-rdd.xml")
# 2.2.2.IgniteRDD
IgniteRDD是一个SparkRDD抽象的实现,它表示Ignite的缓存的活动视图。IgniteRDD不是一成不变的,Ignite缓存的所有改变(不论是它被另一个RDD或者缓存的外部改变触发)对于RDD用户都会立即可见。
IgniteRDD利用Ignite缓存的分区性质然后向Spark执行器提供分区信息。IgniteRDD中分区的数量会等于底层Ignite缓存的分区数量,IgniteRDD还通过getPrefferredLocations方法向Spark提供了关联信息使RDD计算可以使用本地的数据。
# 2.2.3.从Ignite中读取数据
因为IgniteRDD是Ignite缓存的一个活动视图,因此不需要从Ignite向Spark应用显式地加载数据,在IgniteRDD实例创建之后所有的RDD方法都会立即可用。
比如,假定一个名为partitioned的Ignite缓存包含字符值,下面的代码会查找包含单词Ignite的所有值:
val cache = igniteContext.fromCache("partitioned")
val result = cache.filter(_._2.contains("Ignite")).collect()
# 2.2.4.向Ignite保存数据
因为Ignite缓存操作于键-值对,因此向Ignite缓存保存数据的最明确的方法是使用Spark数组RDD以及savePairs方法,如果可能,这个方法会利用RDD分区的优势然后以并行的方式将数据存入缓存。
也可能使用saveValues方法将只有值的RDD存入Ignite缓存,这时,IgniteRDD会为每个要存入缓存的值生成一个唯一的本地关联键。
比如,下面的代码会使用10个并行存储操作保存从1到10000的整型值对到一个名为partitioned的缓存中:
val cacheRdd = igniteContext.fromCache("partitioned")
cacheRdd.savePairs(sparkContext.parallelize(1 to 10000, 10).map(i => (i, i)))
# 2.2.5.在Ignite缓存中执行SQL查询
当Ignite缓存配置为启用索引子系统,就可以使用objectSql和sql方法在缓存中执行SQL查询。可以参照使用SQL章节来了解有关Ignite SQL查询的更多信息。
比如,假定名为partitioned的缓存配置了索引整型对,下面的代码会获得 (10, 100)范围内的所有整型值:
val cacheRdd = igniteContext.fromCache("partitioned")
val result = cacheRdd.sql(
"select _val from Integer where val > ? and val < ?", 10, 100)
# 2.2.6.示例
GitHub上有一些示例,演示了IgniteRDD如何使用:
# 2.3.Ignite DataFrame
# 2.3.1.概述
Spark DataFrame API引入了描述数据的模式的概念,这样Ignite就可以管理模式并且将数据组织成表格的形式。简单来说,DataFrame就是一个将数据组织成命名列的分布式集合,它在概念上等价于关系数据库中的表,Spark会利用催化剂查询优化器的优势,生成一个比RDD更高效的查询执行计划,而RDD只是一个集群范围的、分区化的元素的集合。
Ignite扩展了DataFrame,简化了开发,并且如果Ignite用作Spark的内存存储,还会改进数据访问的时间,好处包括:
- 通过在Ignite中读写DataFrame,可以在Spark作业间共享数据和状态;
- 使用Ignite的SQL引擎,包括高级索引以及避免Ignite和Spark之间的网络数据移动,可以优化Spark的查询执行计划,从而实现更快的SparkSQL查询。
# 2.3.2.集成
IgniteRelationProvider是SparkRelationProvider和CreatableRelationProvider接口的一个实现,IgniteRelationProvider可以通过SparkSQL接口,直接访问Ignite表。数据通过IgniteSQLRelation进行加载和交换,其在Ignite端执行过滤操作。目前,分组、联接或者排序操作,是在Spark端进行的,在即将发布的版本中,这些操作会在Ignite端进行优化和处理。IgniteSQLRelation利用了Ignite架构的分区特性,并且为Spark提供了分区信息。
# 2.3.3.Spark会话
如果要使用Spark DataFrame API,需要为Spark编程创建一个入口点,这是通过SparkSession对象实现的,大体如下:
# 2.3.4.读取DataFrame
要从Ignite中读取数据,需要指定格式以及Ignite配置文件的路径,假定如下名为person的Ignite表已经创建和部署:
CREATE TABLE person (
id LONG,
name VARCHAR,
city_id LONG,
PRIMARY KEY (id, city_id)
) WITH "backups=1, affinityKey=city_id”;
下面的Spark代码可以从person表检索到名字为Mary Major的所有行:
# 2.3.5.保存DataFrames
实现细节
从内部来说,所有的插入操作都是通过IgniteDataStreamer实现的,内部的流处理器是可以通过参数进行控制的。
Ignite可以作为Spark创建和维护的DataFrame的存储层,下面的保存模式,决定了Ignite中DataFrame的处理方式:
Append:DataFrame会附加到一个已有的表,如果要更新DataFrame中的已有条目,可以配置OPTION_STREAMER_ALLOW_OVERWRITE=true;Overwrite:会执行如下的步骤:- 如果Ignite中的表已经存在,那么会被删除;
- 会使用DataFrame的模式以及参数创建新的表;
- DataFrame的内容会被插入新的表。
ErrorIfExists:(默认),如果表已经存在会抛出异常,表不存在时:- 会使用DataFrame的模式以及参数创建新的表;
- DataFrame的内容会被插入新的表。
Ignore:如果表已经存在会被忽略,表不存在时:- 会使用DataFrame的模式以及参数创建新的表;
- DataFrame的内容会被插入新的表。
保存模式可以通过mode(SaveMode mode)方法指定,具体可以参照Spark的文档,下面是该方法的一个示例:
如果是通过保存DataFrame的途径创建的新表,那么必须定义下面的选项:
OPTION_CREATE_TABLE_PRIMARY_KEY_FIELDS:Ignite表的主键,该选项的内容为代表主键的、逗号分隔的字段/列列表;OPTION_CREATE_TABLE_PARAMETERS:用于Ignite表创建的附加参数,该参数为Ignite的CREATE TABLE命令支持的参数。
下面的示例展示了如何将JSON文件的内容写入Ignite:
# 2.3.6.IgniteSparkSession和IgniteExternalCatalog
针对已知数据源(比如表和视图)的元信息的读取和存储,Spark引入了叫做catalog的实体,关于这个目录,Ignite提供了自己的实现,叫做IgniteExternalCatalog。
IgniteExternalCatalog可以读取部署在Ignite集群中的所有SQL表的元数据信息,如果要构造IgniteSparkSession对象,IgniteExternalCatalog也是必要的。
IgniteSparkSession是正常SparkSession的一个扩展,它存储了IgniteContext,并且在Spark对象中注入了IgniteExternalCatalog。
IgniteSparkSession可以用IgniteSparkSession.builder()进行创建,比如,如果下面的两张表已经创建好:
CREATE TABLE city (
id LONG PRIMARY KEY,
name VARCHAR
) WITH "template=replicated";
CREATE TABLE person (
id LONG,
name VARCHAR,
city_id LONG,
PRIMARY KEY (id, city_id)
) WITH "backups=1, affinityKey=city_id";
然后执行下面的代码,列出表的元数据信息:
代码输出大体如下:
+------+--------+-----------+---------+-----------+
| name|database|description|tableType|isTemporary|
+------+--------+-----------+---------+-----------+
| CITY| | null| EXTERNAL| false|
|PERSON| | null| EXTERNAL| false|
+------+--------+-----------+---------+-----------+
PERSON table description:
+-------+-----------+--------+--------+-----------+--------+
| name|description|dataType|nullable|isPartition|isBucket|
+-------+-----------+--------+--------+-----------+--------+
| NAME| null| string| true| false| false|
| ID| null| bigint| false| true| false|
|CITY_ID| null| bigint| false| true| false|
+-------+-----------+--------+--------+-----------+--------+
CITY table description:
+----+-----------+--------+--------+-----------+--------+
|name|description|dataType|nullable|isPartition|isBucket|
+----+-----------+--------+--------+-----------+--------+
|NAME| null| string| true| false| false|
| ID| null| bigint| false| true| false|
+----+-----------+--------+--------+-----------+--------+
# 2.3.7.Ignite DataFrame选项
| 参数 | 描述 |
|---|---|
FORMAT_IGNITE | Ignite数据源的名字 |
OPTION_CONFIG_FILE | 配置文件的路径 |
OPTION_TABLE | 表名 |
OPTION_CREATE_TABLE_PARAMETERS | 新创建表的额外参数,该选项的值用作CREATE TABLE语句的WITH部分。 |
OPTION_CREATE_TABLE_PRIMARY_KEY_FIELDS | 逗号分隔的主键字段的列表。 |
OPTION_STREAMER_ALLOW_OVERWRITE | 如果为true,那么已有的行会被DataFrame的内容覆写,如果为false并且表中对应的主键已经存在,那么后续该行会被忽略。 |
OPTION_STREAMER_FLUSH_FREQUENCY | 自动刷新频率,这是流处理器尝试提交所有附加数据到远程节点的时间间隔。 |
OPTION_STREAMER_PER_NODE_BUFFER_SIZE | 每节点的缓冲区大小。每个节点键-值对缓冲区的大小。 |
OPTION_STREAMER_PER_NODE_PARALLEL_OPERATIONS | 每节点的缓冲区大小。每个节点进行并行流处理的最大数量。 |
# 2.3.8.示例
GitHub上有一些用于演示如何在Ignite中使用Spark DataFrame的示例:
# 2.4.安装
# 2.4.1.共享部署
共享部署意味着Ignite节点的运行独立于Spark应用然后即使Spark作业结束之后也仍然保存状态。类似于Spark,将Ignite部署入集群有两种方式:
# 2.4.1.1.独立部署
在独立部署模式,Ignite节点应该与Spark工作节点部署在一起。Ignite安装的介绍可以参照安装章节,在所有的工作节点上安装Ignite之后,通过ignite.sh脚本在每个配置好的Spark工作节点上启动一个节点。
# 2.4.1.2.默认将Ignite库文件加入Spark类路径
Spark应用部署模型可以在应用启动期间动态地发布jar,但是这个模式有一些缺点:
- Spark动态类加载器没有实现
getResource方法,因此无法访问位于jar文件内部的资源; - Java的logger使用应用级类加载器(而不是上下文级类加载器)来加载日志处理器,这会导致在Ignite中使用Java logging时会抛出
ClassNotFoundException;
有一个方法来对每一个启动的应用修改默认的Spark类路径(这个可以在每个Spark集群的机器上实现,包括主节点,工作节点以及驱动节点)。
- 定位到
$SPARK_HOME/conf/spark-env.sh文件,如果该文件不存在,用$SPARK_HOME/conf/spark-env.sh.template这个模板创建它; - 将下面的行加入
spark-env.sh文件的末尾(如果没有全局定义IGNITE_HOME,则需要将设置IGNITE_HOME的行的注释去掉)。
# Optionally set IGNITE_HOME here.
# IGNITE_HOME=/path/to/ignite
IGNITE_LIBS="${IGNITE_HOME}/libs/*"
for file in ${IGNITE_HOME}/libs/*
do
if [ -d ${file} ] && [ "${file}" != "${IGNITE_HOME}"/libs/optional ]; then
IGNITE_LIBS=${IGNITE_LIBS}:${file}/*
fi
done
export SPARK_CLASSPATH=$IGNITE_LIBS
从$IGNITE_HOME/libs/optional文件夹中复制必要的库文件,比如ignite-log4j,到$IGNITE_HOME/libs文件夹。
也可以验证Spark的类路径是否被运行bin/spark-shell所改变,然后输入一个简单的import语句:
scala> import org.apache.ignite.configuration._
import org.apache.ignite.configuration._
# 2.4.2.嵌入式部署
嵌入式模式已被废弃
嵌入式模式意味着需要在Spark执行器中启动Ignite服务端节点,这可能导致意外的再平衡甚至数据丢失,因此该模式目前已被弃用并且最终会被废弃。可以考虑启动一个单独的Ignite集群然后使用独立模式来避免数据的一致性和性能问题。
嵌入式部署意味着Ignite节点是在Spark作业进程内部启动的,然后当作业结束时就停止了,这时不需要额外的部署步骤。Ignite代码会通过Spark的部署机制分布到Spark工作节点然后作为IgniteContext初始化的一部分在所有的Spark工作节点上启动节点。
# 2.4.3.Maven
Ignite的Spark构件已经上传到Maven中心库,根据使用的Scala版本,引入下面的对应的依赖:
# 2.4.4.SBT
如果在Scala应用中使用SBT作为构建工具,那么可以使用下面的一行命令,将Ignite的Spark构件加入build.sbt:
libraryDependencies += "org.apache.ignite" % "ignite-spark-ext" % "2.0.0"
# 2.4.5.类路径配置
当使用IgniteRDD或者Ignite的DataFrame API时,要注意Spark的执行器以及驱动在它们的类路径中所有必需的Ignite的jar包都是可用的,Spark提供了若干种方式来修改驱动或者执行器进程的类路径。
# 2.4.5.1.参数配置
通过使用比如spark.driver.extraClassPath以及spark.executor.extraClassPath这样的参数,可以将Ignite的jar包加入Spark,具体可以看Spark的官方文档。
下面的片段演示了如何使用spark.driver.extraClassPath参数:
spark.executor.extraClassPath /opt/ignite/libs/*:/opt/ignite/libs/optional/ignite-spark-ext/*:/opt/ignite/libs/optional/ignite-log4j2/*:/opt/ignite/libs/optional/ignite-yarn-ext/*:/opt/ignite/libs/ignite-spring/*
# 2.4.5.2.源代码配置
Spark也提供了在源代码中配置额外的库的API,比如像下面的代码片段:
private val MAVEN_HOME = "/home/user/.m2/repository"
val spark = SparkSession.builder()
.appName("Spark Ignite data sources example")
.master("spark://172.17.0.2:7077")
.getOrCreate()
spark.sparkContext.addJar(MAVEN_HOME + "/org/apache/ignite/ignite-core/2.4.0/ignite-core-2.4.0.jar")
spark.sparkContext.addJar(MAVEN_HOME + "/org/apache/ignite/ignite-spring/2.4.0/ignite-spring-2.4.0.jar")
spark.sparkContext.addJar(MAVEN_HOME + "/org/apache/ignite/ignite-log4j/2.4.0/ignite-log4j-2.4.0.jar")
spark.sparkContext.addJar(MAVEN_HOME + "/org/apache/ignite/ignite-spark/2.4.0/ignite-spark-2.4.0.jar")
spark.sparkContext.addJar(MAVEN_HOME + "/org/apache/ignite/ignite-indexing/2.4.0/ignite-indexing-2.4.0.jar")
spark.sparkContext.addJar(MAVEN_HOME + "/org/springframework/spring-beans/4.3.7.RELEASE/spring-beans-4.3.7.RELEASE.jar")
spark.sparkContext.addJar(MAVEN_HOME + "/org/springframework/spring-core/4.3.7.RELEASE/spring-core-4.3.7.RELEASE.jar")
spark.sparkContext.addJar(MAVEN_HOME + "/org/springframework/spring-context/4.3.7.RELEASE/spring-context-4.3.7.RELEASE.jar")
spark.sparkContext.addJar(MAVEN_HOME + "/org/springframework/spring-expression/4.3.7.RELEASE/spring-expression-4.3.7.RELEASE.jar")
spark.sparkContext.addJar(MAVEN_HOME + "/javax/cache/cache-api/1.0.0/cache-api-1.0.0.jar")
spark.sparkContext.addJar(MAVEN_HOME + "/com/h2database/h2/1.4.195/h2-1.4.195.jar")
# 2.5.用Spark-shell测试Ignite
# 2.5.1.启动集群
这里会简要地介绍Spark和Ignite集群的启动过程,可以参照Spark文档来了解详细信息。
为了测试,需要一个Spark主节点以及至少一个Spark工作节点,通常Spark主节点和Spark工作节点是不同的机器,但是为了测试可以在启动主节点的同一台机器上启动工作节点。
- 下载和解压Spark二进制包到所有节点的同一个位置(将其设为
SPARK_HOME); - 下载和解压Ignite二进制包到所有节点的同一个位置(将其设为
IGNITE_HOME); - 转到
$SPARK_HOME然后执行如下的命令:这个脚本会输出启动过程的日志文件的路径,可以在日志文件中查看master的URL,它的格式是:sbin/start-master.shspark://master_host:master_port。也可以在日志文件中查看WebUI的URL(通常是http://master_host:8080)。 - 转到每个工作节点的
$SPARK_HOME然后执行如下的命令:这里的bin/spark-class org.apache.spark.deploy.worker.Worker spark://master_host:master_portspark://master_host:master_port就是从上述的主节点的日志文件中抓取的主节点的URL。在所有的工作节点都启动之后可以查看主节点的WebUI界面,它会显示所有的处于ALIVE状态的已经注册的工作节点。 - 转到每个工作节点的
$IGNITE_HOME目录然后通过运行如下的命令启动一个Ignite节点:bin/ignite.sh
这时可以看到通过默认的配置Ignite节点会彼此发现对方。如果网络不允许多播通信,那么需要修改默认的配置文件然后配置TCP发现。
# 2.5.2.使用Spark-Shell
现在,在集群启动运行之后,可以运行spark-shell来验证这个集成:
启动spark-shell:
- 还可能需要提供Ignite部件的Maven坐标(如果需要,可以使用
--repositories参数,但是它可能会被忽略):
./bin/spark-shell --packages org.apache.ignite:ignite-spark-ext:2.0.0 --master spark://master_host:master_port --repositories http://repo.maven.apache.org/maven2/org/apache/ignite- 或者也可以通过
--jars参数提供指向Ignite的jar文件的路径:
./bin/spark-shell --jars path/to/ignite-core.jar,path/to/ignite-spark-ext.jar,path/to/cache-api.jar,path/to/ignite-log4j2.jar,path/to/log4j.jar --master spark://master_host:master_port这时可以看到Spark shell已经启动了。
注意,如果打算使用Spring的配置进行加载,则需要同时添加
ignite-spring的依赖。./bin/spark-shell --packages org.apache.ignite:ignite-spark-ext:2.0.0,org.apache.ignite:ignite-spring:2.13.0 --master spark://master_host:master_port- 还可能需要提供Ignite部件的Maven坐标(如果需要,可以使用
通过默认的配置创建一个Ignite上下文的实例:
import org.apache.ignite.spark._ import org.apache.ignite.configuration._ val ic = new IgniteContext(sc, () => new IgniteConfiguration())然后可以看到一些像下面这样的:
ic: org.apache.ignite.spark.IgniteContext = org.apache.ignite.spark.IgniteContext@62be2836创建一个IgniteContext实例的另一个方式是使用一个配置文件,注意如果指向配置文件的路径是相对形式的,那么
IGNITE_HOME环境变量应该是在系统中全局设定的,因为路径的解析是相对于IGNITE_HOME的。import org.apache.ignite.spark._ import org.apache.ignite.configuration._ val ic = new IgniteContext(sc, "examples/config/spark/example-shared-rdd.xml")通过使用默认配置中的"partitioned"缓存创建一个IgniteRDD的实例:
val sharedRDD = ic.fromCache[Integer, Integer]("partitioned")然后可以看到为partitioned缓存创建了一个RDD的实例:
shareRDD: org.apache.ignite.spark.IgniteRDD[Integer,Integer] = IgniteRDD[0] at RDD at IgniteAbstractRDD.scala:27注意RDD的创建是一个本地的操作,并不会在Ignite集群上创建缓存。
这时可以用RDD让Spark做一些事情,比如,获取值小于10的所有键-值对:
sharedRDD.filter(_._2 < 10).collect()因为缓存还没有数据,因此结果会是一个空的数组:
res0: Array[(Integer, Integer)] = Array()可以查看远程spark工作节点的日志文件然后可以看到Ignite上下文如何在集群内的所有远程工作节点上启动客户端。也可以启动命令行Visor然后查看
partitioned缓存已经创建了。在Ignite中保存一些值:
sharedRDD.savePairs(sc.parallelize(1 to 100000, 10).map(i => (i, i)))运行这个命令后可以通过命令行Visor查看缓存的大小是100000个元素。
现在要检查之前创建的状态在作业重启之后如何保持,关闭spark-shell然后重复步骤1-3,这时会再一次为partitioned缓存创建了Ignite上下文和RDD的实例,现在可以查看在RDD中有多少值大于50000的键:
sharedRDD.filter(_._2 > 50000).count因为在缓存中加入了从1到100000的连续数值,那么会得到结果
50000:res0: Long = 50000
# 2.6.发现并解决的问题
在IgniteRDD上调用任何活动时Spark应用或者Spark shell没有响应
如果在客户端模式(默认模式)下创建
IgniteContext然后又没有任何Ignite服务端节点启动时,就会发生这种情况,这时Ignite客户端会一直等待服务端节点启动或者超过集群连接超时时间后失败。当在客户端节点使用IgniteContext时应该启动至少一个服务端节点。当使用IgniteContext时,抛出了
java.lang.ClassNotFoundException和org.apache.ignite.logger.java.JavaLoggerFileHandler在类路径中没有任何日志实现然后Ignite会试图使用标准的Java日志时,这个问题就会发生。Spark默认会使用单独的类加载器加载用户的所有jar文件,而Java日志框架是使用应用级类加载器来初始化日志处理器。要解决这个问题,可以将
ignite-log4j2模块加入使用的jar列表以使Ignite使用log4J2作为日志记录器,或者就像安装章节中描述的那样修改Spark的默认类路径。
# 3.Hibernate二级缓存
# 3.1.概述
Ignite可以用做Hibernate的二级缓存,它可以显著地提升应用持久化层的性能。
Hibernate数据库映射对象的所有工作都是在一个会话中完成的,通常绑定到一个工作节点线程或者Web会话。Hibernate默认只会使用Session级的缓存(一级缓存),因此,缓存在一个会话中的对象,对于另一个会话是不可见的。不过如果用的是全局二级缓存,它缓存的所有对象对于用同一个缓存配置的所有会话都是可见的。这通常会带来性能的显著提升,因为每一个新创建的会话都可以利用二级缓存(它比任何会话级L1缓存都要长寿)中已有的数据的好处。
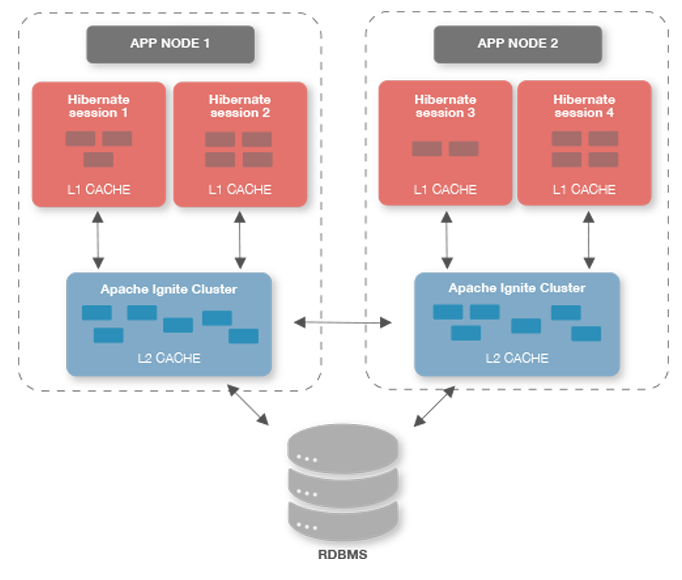
一级缓存是一直启用的而且是由Hibernate内部实现的,而二级缓存是可选的而且有很多的可插拔的实现。Ignite可以作为L2缓存的实现非常容易地嵌入,而且可以用于所有的访问模式(READ_ONLY,READ_WRITE,NONSTRICT_READ_WRITE和TRANSACTIONAL),支持广泛的相关特性:
- 缓存到内存和磁盘以及堆外内存;
- 缓存事务;
- 集群,有2种不同的复制模式,
复制和分区。
如果要将Ignite作为Hibernate的二级缓存,需要简单的3个步骤:
- 将Ignite的库文件添加到应用的类路径;
- 启用二级缓存以及在二级缓存的配置文件中指定Ignite的实现类;
- 为二级缓存配置Ignite缓存区域以及启动嵌入式的Ignite节点(也可以选择外部的节点)。
本章节的后面会详细介绍这些步骤的细节。
# 3.2.二级缓存配置
警告
从Ignite的2.14版本开始,ignite-hibernate模块被移入Ignite的扩展库。
要将Ignite配置为Hibernate的二级缓存,不需要修改已有的Hibernate代码,只需要:
- 根据使用的Hibernate版本不同,在工程中将
ignite-hibernate模块的5.3.0、5.1.0或者4.2.0版本加入依赖,或者,如果是从命令行启动节点,也可以从{apache_ignite_release}/libs/optional中拷贝同名的jar文件到{apache_ignite_release}/libs文件夹; - 配置Hibernate使用Ignite作为二级缓存;
- 正确地配置Ignite缓存。
# 3.2.1.Maven配置
要在项目中添加Ignite-hibernate集成,需要将下面的依赖加入POM文件:
# 3.2.2.Hibernate配置示例
一个用Ignite配置Hibernate二级缓存的典型例子看上去像下面这样:
<hibernate-configuration>
<session-factory>
...
<!-- Enable L2 cache. -->
<property name="cache.use_second_level_cache">true</property>
<!-- Generate L2 cache statistics. -->
<property name="generate_statistics">true</property>
<!-- Specify Ignite as L2 cache provider. -->
<property name="cache.region.factory_class">org.apache.ignite.cache.hibernate.HibernateRegionFactory</property>
<!-- Specify the name of the grid, that will be used for second level caching. -->
<property name="org.apache.ignite.hibernate.ignite_instance_name">hibernate-grid</property>
<!-- Set default L2 cache access type. -->
<property name="org.apache.ignite.hibernate.default_access_type">READ_ONLY</property>
<!-- Specify the entity classes for mapping. -->
<mapping class="com.mycompany.MyEntity1"/>
<mapping class="com.mycompany.MyEntity2"/>
<!-- Per-class L2 cache settings. -->
<class-cache class="com.mycompany.MyEntity1" usage="read-only"/>
<class-cache class="com.mycompany.MyEntity2" usage="read-only"/>
<collection-cache collection="com.mycompany.MyEntity1.children" usage="read-only"/>
...
</session-factory>
</hibernate-configuration>
这里,做了如下工作:
- 开启了二级缓存(可选地生成二级缓存的统计)
- 指定Ignite作为二级缓存的实现
- 指定缓存网格的名字(需要和Ignite配置文件中的保持一致)
- 指定实体类以及为每个类配置缓存(Ignite中应该配置一个相应的缓存区域)
# 3.2.3.Ignite配置示例
一个典型的支持Hibernate二级缓存的Ignite配置,像下面这样:
<!-- Basic configuration for atomic cache. -->
<bean id="atomic-cache" class="org.apache.ignite.configuration.CacheConfiguration" abstract="true">
<property name="cacheMode" value="PARTITIONED"/>
<property name="atomicityMode" value="ATOMIC"/>
<property name="writeSynchronizationMode" value="FULL_SYNC"/>
</bean>
<!-- Basic configuration for transactional cache. -->
<bean id="transactional-cache" class="org.apache.ignite.configuration.CacheConfiguration" abstract="true">
<property name="cacheMode" value="PARTITIONED"/>
<property name="atomicityMode" value="TRANSACTIONAL"/>
<property name="writeSynchronizationMode" value="FULL_SYNC"/>
</bean>
<bean id="ignite.cfg" class="org.apache.ignite.configuration.IgniteConfiguration">
<!--
Specify the name of the caching grid (should correspond to the
one in Hibernate configuration).
-->
<property name="igniteInstanceName" value="hibernate-grid"/>
...
<!--
Specify cache configuration for each L2 cache region (which corresponds
to a full class name or a full association name).
-->
<property name="cacheConfiguration">
<list>
<!--
Configurations for entity caches.
-->
<bean parent="transactional-cache">
<property name="name" value="com.mycompany.MyEntity1"/>
</bean>
<bean parent="transactional-cache">
<property name="name" value="com.mycompany.MyEntity2"/>
</bean>
<bean parent="transactional-cache">
<property name="name" value="com.mycompany.MyEntity1.children"/>
</bean>
<!-- Configuration for update timestamps cache. -->
<bean parent="atomic-cache">
<property name="name" value="org.hibernate.cache.spi.UpdateTimestampsCache"/>
</bean>
<!-- Configuration for query result cache. -->
<bean parent="atomic-cache">
<property name="name" value="org.hibernate.cache.internal.StandardQueryCache"/>
</bean>
</list>
</property>
...
</bean>
上面的代码为每个二级缓存区域指定了缓存的配置:
- 使用
分区缓存在缓存节点间拆分数据,其它的策略也可以选择复制模式,这样就在所有缓存节点上复制完整的数据集,可以参照相关的章节以了解更多的信息。 - 指定与二级缓存区域名一致的缓存名(或者是完整类名或者是完整的关系名)
- 用
事务原子化模式来利用缓存事务的优势 - 开启
FULL_SYNC模式保持备份节点的完全同步
另外,指定了一个缓存来更新时间戳,它可以是原子化的,因为性能好。
配置完Ignite缓存节点后,可以通过如下方式在节点内启动它:
Ignition.start("my-config-folder/my-ignite-configuration.xml");
上述代码执行完毕后,内部的节点就启动了然后准备缓存数据,也可以从控制台执行如下命令来启动额外的独立的节点:
提示
节点也可以在其它主机上启动,以形成一个分布式的缓存集群,一定要确保在配置文件中指定正确的网络参数。
# 3.3.查询缓存
除了二级缓存,Hibernate还提供了查询缓存,这个缓存存储了通过指定参数集进行查询的结果(或者是HQL或者是Criteria),因此,当重复用同样的参数集进行查询时,它会命中缓存而不会去访问数据库。
查询缓存对于反复用同样的参数集进行查询时是有用的。像二级缓存的场景一样,Hibernate依赖于一个第三方的缓存实现,Ignite也可以这样用。
# 3.4.查询缓存配置
上面的配置信息完全适用于查询缓存,但是额外的配置和代码变更还是必要的。
# 3.4.1.Hibernate配置
要在Hibernate种启用查询缓存,只需要在配置文件中添加额外的一行:
<!-- Enable query cache. -->
<property name="cache.use_query_cache">true</property>
然后,需要对代码做出修改,对于要缓存的每一个查询,都需要通过调用setCacheable(true)来开启cacheable标志。
Session ses = ...;
// Create Criteria query.
Criteria criteria = ses.createCriteria(cls);
// Enable cacheable flag.
criteria.setCacheable(true);
...
这个完成之后,查询结果就会被缓存了。
# 3.4.2.Ignite配置
要在Ignite中开启Hibernate查询缓存,需要指定一个额外的缓存配置:
<property name="cacheConfiguration">
<list>
...
<!-- Query cache (refers to atomic cache defined in above example). -->
<bean parent="atomic-cache">
<property name="name" value="org.hibernate.cache.internal.StandardQueryCache"/>
</bean>
</list>
</property>
# 3.5.示例
GitHub上有完整的示例。
# 4.MyBatis二级缓存
Ignite可以作为MyBatis的二级缓存使用,从而在整个集群中分布和缓存数据。
如果是一个Maven用户,可以简单地在pom.xml中添加如下的依赖:
<dependencies>
...
<dependency>
<groupId>org.mybatis.caches</groupId>
<artifactId>mybatis-ignite</artifactId>
<version>1.0.5</version>
</dependency>
...
</dependencies>
或者,也可以下载zip包,解压缩之后将jar文件加入类路径。
然后,只需要像下面这样在映射XML文件中指定即可:
<mapper namespace="org.acme.FooMapper">
<cache type="org.mybatis.caches.ignite.IgniteCacheAdapter" />
</mapper>
然后在config/default-config.xml中配置Ignite缓存(可以简单地参考下GitHub中的配置)。
# 5.流处理
# 5.1.Kafka流处理器
# 5.1.1.概述
Apache Ignite的Kafka流处理器模块提供了从Kafka到Ignite缓存的流处理功能,下面两个方法中的任何一个都可以用于获得这样的流处理功能:
- 使用带有Ignite接收器的Kafka连接器功能;
- 在Maven工程中导入Kafka的流处理器模块然后实例化KafkaStreamer用于数据流处理。
# 5.1.2.通过Kafka Connect的数据流
通过从Kafka的主题拉取数据然后将其写入某个Ignite缓存,IgniteSinkConnector可以用于将数据从Kafka导入Ignite缓存。
连接器位于optional/ignite-kafka,它和它的依赖需要位于一个Kafka运行实例的类路径中,下面会详细描述。关于Kafka Connect的更多信息,可以参考Kafka文档。
# 5.1.2.1.设置和运行
- 将下面的jar包放入Kafka的类路径:
ignite-kafka-x.x.x.jar <-- with IgniteSinkConnector ignite-core-x.x.x.jar cache-api-1.0.0.jar ignite-spring-1.5.0-SNAPSHOT.jar spring-aop-4.1.0.RELEASE.jar spring-beans-4.1.0.RELEASE.jar spring-context-4.1.0.RELEASE.jar spring-core-4.1.0.RELEASE.jar spring-expression-4.1.0.RELEASE.jar commons-logging-1.1.1.jar - 准备工作节点的配置,比如;
bootstrap.servers=localhost:9092 key.converter=org.apache.kafka.connect.storage.StringConverter value.converter=org.apache.kafka.connect.storage.StringConverter key.converter.schemas.enable=false value.converter.schemas.enable=false internal.key.converter=org.apache.kafka.connect.storage.StringConverter internal.value.converter=org.apache.kafka.connect.storage.StringConverter internal.key.converter.schemas.enable=false internal.value.converter.schemas.enable=false offset.storage.file.filename=/tmp/connect.offsets offset.flush.interval.ms=10000 - 准备连接器的配置,比如:
# connector name=my-ignite-connector connector.class=org.apache.ignite.stream.kafka.connect.IgniteSinkConnector tasks.max=2 topics=someTopic1,someTopic2 # cache cacheName=myCache cacheAllowOverwrite=true igniteCfg=/some-path/ignite.xml singleTupleExtractorCls=my.company.MyExtractor- 这里
cacheName等于some-path/ignite.xml中指定的缓存名,之后someTopic1,someTopic2主题的数据就会被拉取和存储; - 如果希望覆盖缓存中的已有值,可以将
cacheAllowOverwrite设置为true; - 如果需要解析输入的数据然后形成新的键和值,则需要实现一个
StreamSingleTupleExtractor然后像上面那样指定singleTupleExtractorCls; - 还可以设置
cachePerNodeDataSize和cachePerNodeParOps,用于调整每个节点的缓冲区以及每个节点中并行流操作的最大值。
- 这里
- 启动连接器,作为一个示例,像下面这样在独立模式中:
bin/connect-standalone.sh myconfig/connect-standalone.properties myconfig/ignite-connector.properties
# 5.1.2.2.流程检查
要执行一个非常基本的功能检查,可以这样做:
- 启动Zookeeper;
bin/zookeeper-server-start.sh config/zookeeper.properties - 启动Kafka服务:
bin/kafka-server-start.sh config/server.properties - 为Kafka服务提供一些数据:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test --property parse.key=true --property key.separator=, k1,v1 - 启动连接器:
bin/connect-standalone.sh myconfig/connect-standalone.properties myconfig/ignite-connector.properties - 检查缓存中的值,比如,通过REST API:
http://node1:8080/ignite?cmd=size&cacheName=cache1
# 5.1.3.使用Ignite的Kafka流处理器模块的数据流
如果使用Maven来管理项目的依赖,首先要像下面这样添加Kafka流处理器的模块依赖(将${ignite-kafka-ext.version}替换为实际的版本号):
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
...
<dependencies>
...
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-kafka-ext</artifactId>
<version>${ignite-kafka-ext.version}</version>
</dependency>
...
</dependencies>
...
</project>
假定有一个缓存,键和值都是String类型,可以像下面这样启动流处理器:
KafkaStreamer<String, String> kafkaStreamer = new KafkaStreamer<>();
IgniteDataStreamer<String, String> stmr = ignite.dataStreamer("myCache"));
// allow overwriting cache data
stmr.allowOverwrite(true);
kafkaStreamer.setIgnite(ignite);
kafkaStreamer.setStreamer(stmr);
// set the topic
kafkaStreamer.setTopic(someKafkaTopic);
// set the number of threads to process Kafka streams
kafkaStreamer.setThreads(4);
// set Kafka consumer configurations
kafkaStreamer.setConsumerConfig(kafkaConsumerConfig);
// set extractor
kafkaStreamer.setSingleTupleExtractor(strExtractor);
kafkaStreamer.start();
...
// stop on shutdown
kafkaStreamer.stop();
strm.close();
要了解有关Kafka消费者属性的详细信息,可以参照Kafka文档。
# 5.2.Camel流处理器
# 5.2.1.概述
本章节聚焦于Apache Camel流处理器,它也可以被视为一个统一的流处理器,因为它可以从Camel支持的任何技术或者协议中消费消息然后注入一个Ignite缓存。
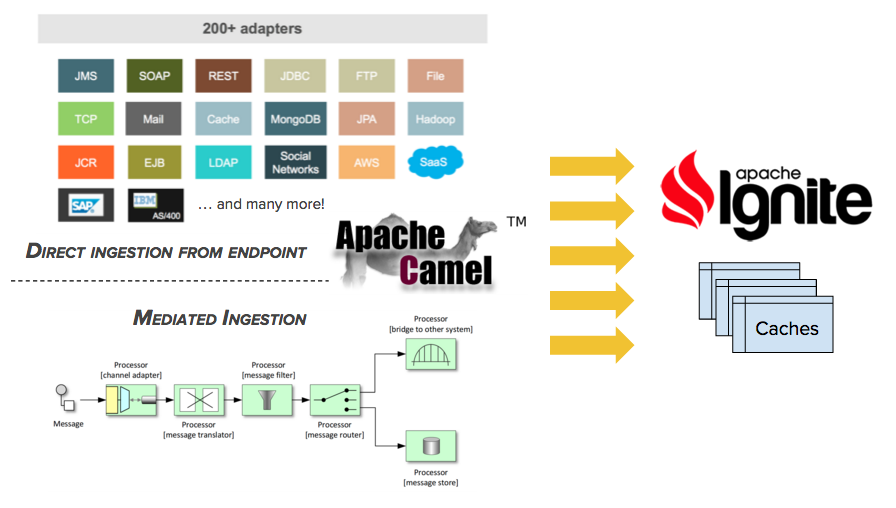
使用这个流处理器,基于如下技术可以将数据条目注入一个Ignite缓存:
- 通过提取消息头和消息体,调用一个Web服务(SOAP或者REST);
- 为消息监听一个TCP或者UDP通道;
- 通过FTP接收文件的内容或者写入本地文件系统;
- 通过POP3或者IMAP发送接收到的消息;
- 一个MongoDB Tailable游标;
- 一个AWS SQS队列;
- 其它的。
这个流处理器支持两种提取模式,直接提取和间接提取。
一个Ignite Camel组件
还有一个camel-ignite组件,通过该组件,可以与Ignite缓存、计算、事件、消息等进行交互。
# 5.2.2.Maven依赖
要使用ignite-camel-ext流处理器,需要添加下面的依赖:
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-camel-ext</artifactId>
<version>${ignite-camel-ext.version}</version>
</dependency>
它也将camel-core作为传递依赖引入。
# 5.2.3.直接提取
直接提取使得通过一个提取器元组的帮助可以从任意Camel端点获得消息然后直接进入Ignite,这个被称为直接提取。
下面是一个代码示例:
// Start Apache Ignite.
Ignite ignite = Ignition.start();
// Create an streamer pipe which ingests into the 'mycache' cache.
IgniteDataStreamer<String, String> pipe = ignite.dataStreamer("mycache");
// Create a Camel streamer and connect it.
CamelStreamer<String, String> streamer = new CamelStreamer<>();
streamer.setIgnite(ignite);
streamer.setStreamer(pipe);
// This endpoint starts a Jetty server and consumes from all network interfaces on port 8080 and context path /ignite.
streamer.setEndpointUri("jetty:http://0.0.0.0:8080/ignite?httpMethodRestrict=POST");
// This is the tuple extractor. We'll assume each message contains only one tuple.
// If your message contains multiple tuples, use a StreamMultipleTupleExtractor.
// The Tuple Extractor receives the Camel Exchange and returns a Map.Entry<?,?> with the key and value.
streamer.setSingleTupleExtractor(new StreamSingleTupleExtractor<Exchange, String, String>() {
@Override public Map.Entry<String, String> extract(Exchange exchange) {
String stationId = exchange.getIn().getHeader("X-StationId", String.class);
String temperature = exchange.getIn().getBody(String.class);
return new GridMapEntry<>(stationId, temperature);
}
});
// Start the streamer.
streamer.start();
# 5.2.4.间接提取
多于更多的复杂场景,也可以创建一个Camel route在输入的消息上执行复杂的处理,比如转换、验证、拆分、聚合、幂等、重新排序、富集等,然后只是将结果注入Ignite缓存,这个被称为间接提取。
// Create a CamelContext with a custom route that will:
// (1) consume from our Jetty endpoint.
// (2) transform incoming JSON into a Java object with Jackson.
// (3) uses JSR 303 Bean Validation to validate the object.
// (4) dispatches to the direct:ignite.ingest endpoint, where the streamer is consuming from.
CamelContext context = new DefaultCamelContext();
context.addRoutes(new RouteBuilder() {
@Override
public void configure() throws Exception {
from("jetty:http://0.0.0.0:8080/ignite?httpMethodRestrict=POST")
.unmarshal().json(JsonLibrary.Jackson)
.to("bean-validator:validate")
.to("direct:ignite.ingest");
}
});
// Remember our Streamer is now consuming from the Direct endpoint above.
streamer.setEndpointUri("direct:ignite.ingest");
# 5.2.5.设置一个响应
响应默认只是简单地将一个原来的请求的副本反馈给调用者(如果是一个同步端点)。如果希望定制这个响应,需要设置一个Camel的Processor作为一个responseProcessor。
streamer.setResponseProcessor(new Processor() {
@Override public void process(Exchange exchange) throws Exception {
exchange.getOut().setHeader(Exchange.HTTP_RESPONSE_CODE, 200);
exchange.getOut().setBody("OK");
}
});
# 5.3.Flink流处理器
Apache Ignite Flink接收器模块是一个流处理连接器,它可以将Flink数据注入Ignite缓存,该接收器会将输入的数据注入Ignite缓存。每当创建一个接收器,都需要提供一个Ignite缓存名和Ignite网格配置文件。
通过如下步骤,可以开启到Ignite缓存的数据注入:
在Maven工程中导入Ignite的Flink接收器模块。如果使用Maven来进行项目依赖管理,可以像下面这样添加Flink模块依赖(将
${ignite-flink-ext.version}替换为实际使用的版本);<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> ... <dependencies> ... <dependency> <groupId>org.apache.ignite</groupId> <artifactId>ignite-flink-ext</artifactId> <version>${ignite-flink-ext.version}</version> </dependency> ... </dependencies> ... </project>创建一个Ignite配置文件,并且确保它可以被Sink访问;
确保输入接收器的数据被指定然后启动接收器;
IgniteSink igniteSink = new IgniteSink("myCache", "ignite.xml"); igniteSink.setAllowOverwrite(true); igniteSink.setAutoFlushFrequency(10); igniteSink.start(); DataStream<Map> stream = ...; // Sink data into the grid. stream.addSink(igniteSink); try { env.execute(); } catch (Exception e){ // Exception handling. } finally { igniteSink.stop(); }
可以参考ignite-flink-ext模块的javadoc来了解可用选项的详细信息。
# 5.4.Flume流处理器
# 5.4.1.概述
Apache Flume是一个高效的收集、汇总以及移动大量的日志数据的分布式的、高可靠和高可用的服务(https://github.com/apache/flume)。
IgniteSink是一个Flume接收器,它会从相对应的Flume通道中提取事件然后将数据注入Ignite缓存。
在启动Flume代理之前,就像下面章节描述的,IgniteSink及其依赖需要包含在代理的类路径中。
# 5.4.2.设置
- 通过实现EventTransformer接口创建一个转换器;
- 在${FLUME_HOME}中的plugins.d目录下创建
ignite子目录,如果plugins.d目录不存在,创建它; - 构建前述的转换器并且拷贝到
${FLUME_HOME}/plugins.d/ignite/lib目录; - 从Ignite二进制包中拷贝其它的Ignite相关的jar包到
${FLUME_HOME}/plugins.d/ignite/libext,如下所示;plugins.d/ `-- ignite |-- lib | `-- ignite-flume-transformer-x.x.x.jar <-- your jar `-- libext |-- cache-api-1.0.0.jar |-- ignite-core-x.x.x.jar |-- ignite-flume-ext-x.x.x.jar <-- IgniteSink |-- ignite-spring-x.x.x.jar |-- spring-aop-4.1.0.RELEASE.jar |-- spring-beans-4.1.0.RELEASE.jar |-- spring-context-4.1.0.RELEASE.jar |-- spring-core-4.1.0.RELEASE.jar `-- spring-expression-4.1.0.RELEASE.jar - 在Flume配置文件中,指定带有缓存属性的Ignite XML配置文件的位置(可以将
flume/src/test/resources/example-ignite.xml作为一个基本的样例),缓存属性中包含要创建缓存的缓存名称(与Ignite配置文件中的相同),EventTransformer的实现类以及可选的批处理大小。所有的属性都显示在下面的表格中(必须项为粗体)。
| 属性名称 | 默认值 | 描述 |
|---|---|---|
channel | - | |
type | 组件类型名,应该为org.apache.ignite.stream.flume.IgniteSink | - |
igniteCfg | Ignite的XML配置文件 | - |
cacheName | 缓存名,与igniteCfg中的一致 | - |
eventTransformer | org.apache.ignite.stream.flume.EventTransformer的实现类名 | - |
batchSize | 每事务要写入的事件数 | 100 |
名字为a1的接收代理配置片段如下所示:
a1.sinks.k1.type = org.apache.ignite.stream.flume.IgniteSink
a1.sinks.k1.igniteCfg = /some-path/ignite.xml
a1.sinks.k1.cacheName = testCache
a1.sinks.k1.eventTransformer = my.company.MyEventTransformer
a1.sinks.k1.batchSize = 100
指定代码和配置后(可以参照Flume的文档),就可以运行Flume的代理了。
# 5.5.JMS流处理器
# 5.5.1.概述
Ignite提供了一个JMS数据流处理器,它会从JMS代理中消费消息,将消息转换为缓存数据格式然后插入Ignite缓存。
这个数据流处理器支持如下的特性:
- 从队列或者主题中消费消息;
- 支持从主题长期订阅;
- 通过
threads参数支持并发的消费者;- 当从队列中消费消息时,这个组件会启动尽可能多的
会话对象,每个都持有单独的MessageListener实例,因此实现了自然的并发; - 当从主题消费消息时,显然无法启动多个线程,因为这样会导致消费重复的消息,因此,通过一个内部的线程池来实现虚拟的并发。
- 当从队列中消费消息时,这个组件会启动尽可能多的
- 通过
transacted参数支持事务级的会话; - 通过
batched参数支持批量的消费,它会对在一个本地JMS事务的范围内接受的消息进行分组(不需要支持XA)。依赖于代理,这个技术提供了一个很高的吞吐量,因为它减少了必要的消息往返确认的量,虽然存在复制消息的开销(特别是在事务的中间发生了一个事件)。- 当达到
batchClosureMillis时间或者会话收到了至少batchClosureSize消息后批次会被提交; - 基于时间的闭包按照设定的频率触发,然后并行地应用到所有的
会话; - 基于大小的闭包会应用到所有单独的
会话(因为事务在JMS中是会话绑定的),因此当该会话消费了那么多消息后就会被触发。 - 两个选项是互相兼容的,可以禁用任何一个,但是当批次启用之后不能两个都启用。
- 当达到
- 支持通过实现特定的
Destination对象或者名字来指定目的地。
本实现已经在Apache ActiveMQ中进行了测试,但是只要客户端库实现了JMS 1.1 规范的所有JMS代理都是支持的。
# 5.5.2.实例化JMS流处理器
实例化JMS流处理器时,需要具体化下面的泛型:
T extends Message:流处理器会接收到的JMSMessage的类型,如果它可以接收多个,可以使用通用的Message类型;K:缓存键的类型;V:缓存值的类型;
要配置JMS流处理器,还需要提供如下的必要属性:
connectionFactory:ConnectionFactory的实例,通过代理进行必要的配置,它也可以是一个ConnectionFactory池;destination或者(destinationName和destinationType):一个Destination对象(通常是一个代理指定的JMSQueue或者Topic接口的实现),或者是目的地名字的组合(队列或者主题名)和到或者Queue或者Topic的Class引用的类型, 在后一种情况下,流处理器通过Session.createQueue(String)或者Session.createTopic(String)来获得一个目的地;transformer:一个MessageTransformer<T, K, V>的实现,它会消化一个类型为T的JMS消息然后产生一个要添加的缓存条目Map<K, V>,它也可以返回null或者空的Map来忽略传入的消息。
# 5.5.3.示例
下面的示例通过String类型的键和String类型的值来填充一个缓存,要消费的TextMessage格式如下:
raulk,Raul Kripalani
dsetrakyan,Dmitriy Setrakyan
sv,Sergi Vladykin
gm,Gianfranco Murador
下面是代码:
// create a data streamer
IgniteDataStreamer<String, String> dataStreamer = ignite.dataStreamer("mycache"));
dataStreamer.allowOverwrite(true);
// create a JMS streamer and plug the data streamer into it
JmsStreamer<TextMessage, String, String> jmsStreamer = new JmsStreamer<>();
jmsStreamer.setIgnite(ignite);
jmsStreamer.setStreamer(dataStreamer);
jmsStreamer.setConnectionFactory(connectionFactory);
jmsStreamer.setDestination(destination);
jmsStreamer.setTransacted(true);
jmsStreamer.setTransformer(new MessageTransformer<TextMessage, String, String>() {
@Override
public Map<String, String> apply(TextMessage message) {
final Map<String, String> answer = new HashMap<>();
String text;
try {
text = message.getText();
}
catch (JMSException e) {
LOG.warn("Could not parse message.", e);
return Collections.emptyMap();
}
for (String s : text.split("\n")) {
String[] tokens = s.split(",");
answer.put(tokens[0], tokens[1]);
}
return answer;
}
});
jmsStreamer.start();
// on application shutdown
jmsStreamer.stop();
dataStreamer.close();
要使用这个组件,必须通过构建系统(Maven, Ivy, Gradle,sbt等)导入如下的模块:
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-jms11-ext</artifactId>
<version>${ignite-jms11-ext.version}</version>
</dependency>
# 5.6.MQTT流处理器
# 5.6.1.概述
该流处理器使用Eclipse Paho作为MQTT客户端,从一个MQTT主题消费消息,然后将键-值对提供给IgniteDataStreamer实例。
必须提供一个流的元组提取器(不管是单条目的,还是多条目的提取器)来处理传入的消息,然后提取元组以插入缓存。
这个流处理器支持:
- 一次订阅一个或者多个主题;
- 为一个主题或者多个主题指定订阅者的QoS;
- 设置MqttConnectOptions以开启比如会话持久化这样的特性;
- 指定客户端ID。如果未指定会生成以及维护一个随机的ID,指导重新连接;
- (重新)连接重试可以通过guava-retrying库实现,重试等待和重试停止是可以配置的;
- 直到客户端第一次连接,都会阻塞start()方法。
# 5.6.2.示例
下面的代码显示了如何使用这个流处理器:
// Start Ignite.
Ignite ignite = Ignition.start();
// Get a data streamer reference.
IgniteDataStreamer<Integer, String> dataStreamer = grid().dataStreamer("mycache");
// Create an MQTT data streamer
MqttStreamer<Integer, String> streamer = new MqttStreamer<>();
streamer.setIgnite(ignite);
streamer.setStreamer(dataStreamer);
streamer.setBrokerUrl(brokerUrl);
streamer.setBlockUntilConnected(true);
// Set a single tuple extractor to extract items in the format 'key,value' where key => Int, and value => String
// (using Guava here).
streamer.setSingleTupleExtractor(new StreamSingleTupleExtractor<MqttMessage, Integer, String>() {
@Override public Map.Entry<Integer, String> extract(MqttMessage msg) {
List<String> s = Splitter.on(",").splitToList(new String(msg.getPayload()));
return new GridMapEntry<>(Integer.parseInt(s.get(0)), s.get(1));
}
});
// Consume from multiple topics at once.
streamer.setTopics(Arrays.asList("def", "ghi", "jkl", "mno"));
// Start the MQTT Streamer.
streamer.start();
要了解有关选项的更多信息,可以参考ignite-mqtt-ext模块的javadoc。
# 5.7.RocketMQ流处理器
这个流处理器模块提供了从Apache RocketMQ到Ignite的流化处理功能。
如果要使用Ignite的RocketMQ流处理器模块:
- 将其导入自己的Maven工程,如果使用Maven管理项目的依赖,需要添加RocketMQ的模块依赖(将
${ignite-rocketmq-ext.version}替换为实际使用的版本),如下所示:<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> ... <dependencies> ... <dependency> <groupId>org.apache.ignite</groupId> <artifactId>ignite-rocketmq-ext</artifactId> <version>${ignite-rocketmq-ext.version}</version> </dependency> ... </dependencies> ... </project> - 实现
StreamSingleTupleExtractor或者StreamMultipleTupleExtractor,看下面的MyTupleExtractor示例。 对于一个简单的实现,可以看看RocketMQStreamerTest.java; - 初始化之后启动:
IgniteDataStreamer<String, byte[]> dataStreamer = ignite.dataStreamer(MY_CACHE)); dataStreamer.allowOverwrite(true); dataStreamer.autoFlushFrequency(10); streamer = new RocketMQStreamer<>(); //configure. streamer.setIgnite(ignite); streamer.setStreamer(dataStreamer); streamer.setNameSrvAddr(NAMESERVER_IP_PORT); streamer.setConsumerGrp(CONSUMER_GRP); streamer.setTopic(TOPIC_NAME); streamer.setMultipleTupleExtractor(new MyTupleExtractor()); streamer.start(); ... // stop on shutdown streamer.stop(); dataStreamer.close();
在javadoc中可以找到更多可用选项的信息。
# 5.8.Storm流处理器
Apache Ignite的Storm流处理器模块提供了从Storm到Ignite缓存的流处理功能。
通过如下步骤可以将数据注入Ignite缓存:
- 在Maven工程中导入Ignite的Storm流处理器模块。如果使用Maven来管理项目的依赖,可以添加Storm模块依赖(将
${ignite-storm-ext.version}替换为实际使用的版本),如下所示:<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> ... <dependencies> ... <dependency> <groupId>org.apache.ignite</groupId> <artifactId>ignite-storm-ext</artifactId> <version>${ignite-storm-ext.version}</version> </dependency> ... </dependencies> ... </project> - 创建一个Ignite配置文件(可以以modules/storm/src/test/resources/example-ignite.xml文件作为示例)并且确保它可以被流处理器访问;
- 确保输入流处理器的键值数据通过名为
ignite的属性指定(或者通过StormStreamer.setIgniteTupleField(...)也可以指定一个不同的)。作为一个示例可以看TestStormSpout.declareOutputFields(...)。 - 为流处理器创建一个拓扑,带有所有依赖制作一个jar文件然后运行如下的命令:
storm jar ignite-storm-streaming-jar-with-dependencies.jar my.company.ignite.MyStormTopology
# 5.9.ZeroMQ流处理器
Ignite的ZeroMQ流处理器模块具有将ZeroMQ数据流注入Ignite缓存的功能。
要将数据流注入Ignite缓存,需要按照如下步骤操作:
- 将Ignite的ZeroMQ流处理器模块加入Maven的
pom.xml文件:<dependencies> ... <dependency> <groupId>org.apache.ignite</groupId> <artifactId>ignite-zeromq-ext</artifactId> <version>${ignite-zeromq-ext.version}</version> </dependency> ... </dependencies> - 要么实现StreamSingleTupleExtractor,要么实现StreamMultipleTupleExtractor,这里可以了解更多的细节。
- 像下面这样设置提取器,并且初始化流处理器:
try (IgniteDataStreamer<Integer, String> dataStreamer = grid().dataStreamer("myCacheName")) { dataStreamer.allowOverwrite(true); dataStreamer.autoFlushFrequency(1); try (IgniteZeroMqStreamer streamer = new IgniteZeroMqStreamer( 1, ZeroMqTypeSocket.PULL, "tcp://localhost:5671", null)) { streamer.setIgnite(grid()); streamer.setStreamer(dataStreamer); streamer.setSingleTupleExtractor(new ZeroMqStringSingleTupleExtractor()); streamer.start(); } }
# 5.10.Twitter流处理器
Ignite的Twitter流处理器模块会从Twitter消费微博然后将转换后的键-值对<tweetId, text>注入Ignite缓存。
要将来自Twitter的数据流注入Ignite缓存,需要:
- 在Maven工程里导入Ignite的twitter模块,如果使用maven来管理项目的依赖,则需要添加如下的依赖,并将
${ignite-twitter-ext.version}替换为实际使用的版本:<dependency> <groupId>org.apache.ignite</groupId> <artifactId>ignite-twitter-ext</artifactId> <version>${ignite-twitter-ext.version}</version> </dependency> - 在代码中配置必要的参数,然后启动流处理器,比如:
IgniteDataStreamer dataStreamer = ignite.dataStreamer("myCache"); dataStreamer.allowOverwrite(true); dataStreamer.autoFlushFrequency(10); OAuthSettings oAuthSettings = new OAuthSettings("setting1", "setting2", "setting3", "setting4"); TwitterStreamer<Integer, String> streamer = new TwitterStreamer<>(oAuthSettings); streamer.setIgnite(ignite); streamer.setStreamer(dataStreamer); Map<String, String> params = new HashMap<>(); params.put("track", "apache, twitter"); params.put("follow", "3004445758"); streamer.setApiParams(params);// Twitter Streaming API params. streamer.setEndpointUrl(endpointUrl);// Twitter streaming API endpoint. streamer.setThreadsCount(8); streamer.start();
可以参考Twitter流API文档来了解各种参数的详细信息。
# 6.Cassandra集成
# 6.1.概述
Ignite的Cassandra集成实现了CacheStore接口,其在Cassandra之上构建了一个高性能的缓存层。
它在功能上和CacheJdbcBlobStore以及CacheJdbcPojoStore的方式几乎是相同的,但是又提供了如下的好处;
- 对于CacheStore的批量操作
loadAll(),writeAll(),deleteAll(),使用Cassandra的异步查询 ,可以提供非常高的性能; - 如果Cassandra中不存在会自动创建所有必要的表(以及键空间),也会为将存储为POJOs的Ignite键值自动检测所有必要的字段,并且创建相应的表结构。因此无需关注Cassandra的表创建DDL语法以及Java到Cassandra的类型映射细节。也可以使用
@QuerySqlField注解为Cassandra表列提供配置(列名、索引、排序); - 可以有选择地为将创建的Cassandra表和键空间指定配置(复制因子、复制策略、Bloom过滤器等);
- 组合BLOB和POJO存储的功能,可以根据喜好存储从Ignite缓存来的键-值对(作为BLOB或者POJO);
- 对于键-值支持标准Java和Kryo序列化,它会以BLOB形式存储于Cassandra;
- 通过为某个缓存指定持久化配置,或者通过使用
@QuerySqlField(index = true)注解自动进行配置的检测,支持Cassandra的二级索引(包括定制索引); - 通过持久化配置,或者通过使用
@QuerySqlField(descending = true)注解自动进行配置的检测,支持Cassandra集群键字段的排序; - 对于POJO的键类,如果它的属性之一加注了
@AffinityKeyMapped注解,也会支持关联并置,这时Ignite缓存中存储在某个节点上的键-值对,也会存储(并置)于Cassandra中的同一个节点上。
Ignite的SQL查询和Cassandra
注意,为了执行SQL查询,需要将Cassandra中的所有数据都加载到Ignite集群,Ignite的SQL引擎不会假设所有的数据都在内存中也不会查询Cassandra。 或者也可以使用Ignite原生的持久化-这是一个分布式的、支持ACID以及兼容SQL的磁盘存储,它可以在存储于内存和磁盘上的数据执行SQL查询。
# 6.2.配置
# 6.2.1.概述
要将Cassandra设置为一个持久化存储,需要将Ignite缓存的CacheStoreFactory设置为org.apache.ignite.cache.store.cassandra.CassandraCacheStoreFactory。
可以通过Spring进行配置,如下所示:
<bean id="ignite.cfg" class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="cacheConfiguration">
<list>
...
<!-- Configuring persistence for "cache1" cache -->
<bean class="org.apache.ignite.configuration.CacheConfiguration">
<property name="name" value="cache1"/>
<!-- Tune on Read-Through and Write-Through mode -->
<property name="readThrough" value="true"/>
<property name="writeThrough" value="true"/>
<!-- Specifying CacheStoreFactory -->
<property name="cacheStoreFactory">
<bean class="org.apache.ignite.cache.store.cassandra.CassandraCacheStoreFactory">
<!-- Datasource configuration bean which is responsible for Cassandra connection details -->
<property name="dataSourceBean" value="cassandraDataSource"/>
<!-- Persistent settings bean which is responsible for the details of how objects will be persisted to Cassandra -->
<property name="persistenceSettingsBean" value="cache1_persistence_settings"/>
</bean>
</property>
</bean>
...
</list>
...
</property>
</bean>
这里有两个主要的属性需要为CassandraCacheStoreFactory设置:
dataSourceBean:org.apache.ignite.cache.store.cassandra.utils.datasource.DataSource类的实例,负责Cassandra数据库连接的所有方面(凭据、联系点、读/写一致性级别、负载平衡策略等);persistenceSettingsBean:org.apache.ignite.cache.store.cassandra.utils.persistence.KeyValuePersistenceSettings类的实例,负责对象如何持久化到Cassandra的所有方面(键空间及其选项、表及其选项、分区和集群键选项、POJO对象字段映射、二级索引、BLOB对象序列化器等)。
下面的章节中这两个Bean及其配置会详细地描述。
# 6.2.2.DataSourceBean
这个bean存储了Cassandra数据库与连接和CRUD操作有关的所有必要信息,下面的表格中显示了所有的属性:
| 属性 | 描述 | 默认值 |
|---|---|---|
user | 连接Cassandra的用户名 | |
password | 连接Cassandra的用户密码 | |
credentials | 提供user和password的Credentials Bean | |
authProvider | 接入Cassandra时使用指定的AuthProvider,当自定义身份认证体系准备就绪时,使用这个方法。 | |
port | 接入Cassandra时使用的端口(如果没有在连接点中提供) | |
contactPoints | Cassandra连接时使用的连接点数组(hostaname:[port]) | |
maxSchemaAgreementWaitSeconds | DDL查询返回前架构协议的最大等待时间 | 10秒 |
protocolVersion | 指定使用Cassandra驱动协议的哪个版本(有助于旧版本Cassandra的后向兼容) | 3 |
compression | 传输中使用的压缩格式,支持的压缩格式包括:snappy,lz4 | |
useSSL | 是否启用SSL | false |
sslOptions | 是否使用提供的选项启用SSL | false |
collectMetrix | 是否启用指标收集 | false |
jmxReporting | 是否启用JMX的指标报告 | false |
fetchSize | 指定查询获取大小,获取大小控制一次获取的结果集的数量 | |
readConsistency | 指定READ查询的一致性级别 | |
writeConsistency | 指定WRITE/DELETE/UPDATE查询的一致性级别 | |
loadBalancingPolicy | 指定要使用的负载平衡策略 | TokenAwarePolicy |
reconnectionPolicy | 指定要使用的重连策略 | ExponentialReconnectionPolicy |
retryPolicy | 指定要使用的重试策略 | DefaultRetryPolicy |
addressTranslater | 指定要使用的地址转换器 | IdentityTranslater |
speculativeExecutionPolicy | 指定要使用 的推理执行策略 | NoSpeculativeExecutionPolicy |
poolingOptions | 指定连接池选项 | |
socketOptions | 指定保持到Cassandra主机的连接的底层Socket选项 | |
nettyOptions | 允许客户端定制Cassandra驱动底层Netty层的钩子 |
# 6.2.3.PersistenceSettingsBean
这个bean存储了对象(键和值)如何持久化到Cassandra数据库的所有细节信息(键空间、表、分区选项、POJO字段映射等)。
org.apache.ignite.cache.store.cassandra.utils.persistence.KeyValuePersistenceSettings的构造器可以通过如下方式创建这个Bean,从一个包含特定结构的XML配置文档的字符串(看下面的代码),或者指向XML文档的资源。
下面是一个XML配置文档的常规示例(持久化描述符),它指定了Ignite缓存的键和值如何序列化/反序列化到/从Cassandra:
<!--
Root container for persistence settings configuration.
Note: required element
Attributes:
1) keyspace [required] - specifies keyspace for Cassandra tables which should be used to store key/value pairs
2) table [required] - specifies Cassandra table which should be used to store key/value pairs
3) ttl [optional] - specifies expiration period for the table rows (in seconds)
-->
<persistence keyspace="my_keyspace" table="my_table" ttl="86400">
<!--
Specifies Cassandra keyspace options which should be used to create provided keyspace if it doesn't exist.
Note: optional element
-->
<keyspaceOptions>
REPLICATION = {'class' : 'SimpleStrategy', 'replication_factor' : 3}
AND DURABLE_WRITES = true
</keyspaceOptions>
<!--
Specifies Cassandra table options which should be used to create provided table if it doesn't exist.
Note: optional element
-->
<tableOptions>
comment = 'A most excellent and useful table'
AND read_repair_chance = 0.2
</tableOptions>
<!--
Specifies persistent settings for Ignite cache keys.
Note: required element
Attributes:
1) class [required] - java class name for Ignite cache key
2) strategy [required] - one of three possible persistent strategies:
a) PRIMITIVE - stores key value as is, by mapping it to Cassandra table column with corresponding type.
Should be used only for simple java types (int, long, String, double, Date) which could be mapped
to corresponding Cassadra types.
b) BLOB - stores key value as BLOB, by mapping it to Cassandra table column with blob type.
Could be used for any java object. Conversion of java object to BLOB is handled by "serializer"
which could be specified in serializer attribute (see below).
c) POJO - stores each field of an object as a column having corresponding type in Cassandra table.
Provides ability to utilize Cassandra secondary indexes for object fields.
3) serializer [optional] - specifies serializer class for BLOB strategy. Shouldn't be used for PRIMITIVE and
POJO strategies. Available implementations:
a) org.apache.ignite.cache.store.cassandra.utils.serializer.JavaSerializer - uses standard Java
serialization framework
b) org.apache.ignite.cache.store.cassandra.utils.serializer.KryoSerializer - uses Kryo
serialization framework
4) column [optional] - specifies column name for PRIMITIVE and BLOB strategies where to store key value.
If not specified column having 'key' name will be used. Shouldn't be used for POJO strategy.
-->
<keyPersistence class="org.mycompany.MyKeyClass" strategy="..." serializer="..." column="...">
<!--
Specifies partition key fields if POJO strategy used.
Note: optional element, only required for POJO strategy in case you want to manually specify
POJO fields to Cassandra columns mapping, instead of relying on dynamic discovering of
POJO fields and mapping them to the same columns of Cassandra table.
-->
<partitionKey>
<!--
Specifies mapping from POJO field to Cassandra table column.
Note: required element
Attributes:
1) name [required] - POJO field name
2) column [optional] - Cassandra table column name. If not specified lowercase
POJO field name will be used.
-->
<field name="companyCode" column="company" />
...
...
</partitionKey>
<!--
Specifies cluster key fields if POJO strategy used.
Note: optional element, only required for POJO strategy in case you want to manually specify
POJO fields to Cassandra columns mapping, instead of relying on dynamic discovering of
POJO fields and mapping them to the same columns of Cassandra table.
-->
<clusterKey>
<!--
Specifies mapping from POJO field to Cassandra table column.
Note: required element
Attributes:
1) name [required] - POJO field name
2) column [optional] - Cassandra table column name. If not specified lowercase
POJO field name will be used.
3) sort [optional] - specifies sort order (asc or desc)
-->
<field name="personNumber" column="number" sort="desc"/>
...
...
</clusterKey>
</keyPersistence>
<!--
Specifies persistent settings for Ignite cache values.
Note: required element
Attributes:
1) class [required] - java class name for Ignite cache value
2) strategy [required] - one of three possible persistent strategies:
a) PRIMITIVE - stores key value as is, by mapping it to Cassandra table column with corresponding type.
Should be used only for simple java types (int, long, String, double, Date) which could be mapped
to corresponding Cassadra types.
b) BLOB - stores key value as BLOB, by mapping it to Cassandra table column with blob type.
Could be used for any java object. Conversion of java object to BLOB is handled by "serializer"
which could be specified in serializer attribute (see below).
c) POJO - stores each field of an object as a column having corresponding type in Cassandra table.
Provides ability to utilize Cassandra secondary indexes for object fields.
3) serializer [optional] - specifies serializer class for BLOB strategy. Shouldn't be used for PRIMITIVE and
POJO strategies. Available implementations:
a) org.apache.ignite.cache.store.cassandra.utils.serializer.JavaSerializer - uses standard Java
serialization framework
b) org.apache.ignite.cache.store.cassandra.utils.serializer.KryoSerializer - uses Kryo
serialization framework
4) column [optional] - specifies column name for PRIMITIVE and BLOB strategies where to store value.
If not specified column having 'value' name will be used. Shouldn't be used for POJO strategy.
-->
<valuePersistence class="org.mycompany.MyValueClass" strategy="..." serializer="..." column="">
<!--
Specifies mapping from POJO field to Cassandra table column.
Note: required element
Attributes:
1) name [required] - POJO field name
2) column [optional] - Cassandra table column name. If not specified lowercase
POJO field name will be used.
3) static [optional] - boolean flag which specifies that column is static withing a given partition
4) index [optional] - boolean flag specifying that secondary index should be created for the field
5) indexClass [optional] - custom index java class name if you want to use custom index
6) indexOptions [optional] - custom index options
-->
<field name="firstName" column="first_name" static="..." index="..." indexClass="..." indexOptions="..."/>
...
...
</valuePersistence>
</persistence>
下面会提供关于持久化描述符配置及其元素的所有细节信息。
# 6.2.3.1.persistence
必要元素
持久化配置的根容器。
| 属性 | 必需 | 描述 |
|---|---|---|
keyspace | 是 | 存储键-值对的Cassandra表的键空间,如果键空间不存在会创建它(如果指定的Cassandra账户持有正确的权限)。 |
table | 否 | 存储键-值对的Cassandra表,如果表不存在会创建它(如果指定的Cassandra账户持有正确的权限)。 |
ttl | 否 | 表数据行的到期时间(秒),要了解有关Cassandra ttl的详细信息,可以参照到期数据。 |
下面的章节中,会看到持久化配置容器中可以放置那些子元素。
# 6.2.3.2.keyspaceOptions
可选元素
创建在持久化配置容器中配置的keyspace属性指定的Cassandra键空间时的可选项。
键空间只有在不存在时才会被创建,并且连接到Cassandra的账户要持有正确的权限。
这个XML元素指定的文本只是创建键空间的Cassandra DDL语句中在WITH关键字之后的一段代码。
# 6.2.3.3.tableOptions
可选元素
创建在持久化配置容器中配置的table属性指定的表时的可选项。
表只有在不存在时才会被创建,并且连接到Cassandra的账户要持有正确的权限。
这个XML元素指定的文本只是创建表的Cassandra DDL语句中在WITH关键字之后的一段代码。
# 6.2.3.4.keyPersistence
必要元素
Ignite缓存键的持久化配置。
这些属性指定了从Ignite缓存中对象如何存储/加载到/从Cassandra表。
| 属性 | 必需 | 描述 |
|---|---|---|
class | 是 | Ignite缓存键的Java类名。 |
strategy | 是 | 指定三个可能的持久化策略之一(看下面的描述),它会控制对象如何存储/加载到/从Cassandra表。 |
serializer | 否 | BLOB策略的序列化器类(可用的实现看下面),PRIMITIVE和POJO策略时无法使用。 |
column | 否 | PRIMITIVE和BLOB策略时存储键的列名,如果不指定,列名为key,对于POJO策略属性无需指定。 |
持久化策略:
| 名称 | 描述 |
|---|---|
PRIMITIVE | 存储对象,通过对应的类型将其映射到Cassandra表列中,只能使用简单的Java类型(int、long、String、double、Date),它们会直接映射到对应的Cassandra类型上,要了解详细的Java到Cassandra的类型映射,点击这里。 |
BLOB | 将对象存储为BLOB,使用BLOB类型将其映射到Cassandra表列,可以使用任何Java对象,Java对象到BLOB的转换是由keyPersistence容器中的serializer属性指定的序列化器处理的。 |
POJO | 将对象的每个属性按照对应的类型存储到Cassandra的表中,对于对象的属性,提供了利用Cassandra二级索引的能力,只能用于遵守Java Bean规范的POJO对象,并且它的属性都是基本Java类型,它们会直接映射到对应的Cassandra类型上。 |
可用的序列化器实现:
| 类名 | 描述 |
|---|---|
| org.apache.ignite.cache.store.cassandra.utils.serializer.JavaSerializer | 使用标准的Java序列化框架 |
| org.apache.ignite.cache.store.cassandra.utils.serializer.KryoSerializer | 使用Kryo序列化框架 |
如果使用了PRIMITIVE和BLOB持久化策略,那么是不需要指定keyPersistence标签的内部元素的,这样的原因是,这两个策略中整个对象都被持久化到Cassandra表中的一列(可以通过column指定)。
如果使用POJO持久化策略,那么有两个策略:
- 让
keyPersistence标签为空,这时,POJO对象类的所有字段都会通过如下的规则自动检测:- 只有那些可以直接映射到对应的Cassandra类型的简单Java类型会被自动检测;
- 字段的发现机制会考虑
@QuerySqlField注解;- 如果指定了
name属性,它会被用作Cassandra表中的列名,否则属性名的小写形式会被用做列名; - 如果为一个映射到集群键列的字段指定了
descending属性,它会被用于指定列的排序规则。
- 如果指定了
- 字段的发现机制会考虑
@AffinityKeyMapped注解,加注这个注解的字段会被认为是分区键(以它们在类中声明的顺序),其它的所有字段都会以集群键处理。 - 如果没有字段加注了
@AffinityKeyMapped注解,所有被发现的字段都会被认为是分区键。
- 在
keyPersistence标签中指定持久化的细节,这时,需要在partitionKey标签中指定映射到Cassandra表列的分区键字段,这个标签只是作为一个映射设置的容器,没有任何属性。作为一个选择(如果打算使用集群键),也可以在clusterKey标签中指定映射到对应Cassandra表列的集群键字段。这个标签只是作为一个映射设置的容器,也没有任何属性。
下面两个章节会详细描述partition和cluster键字段映射的细节(如果选择了上面列表的第二个选项)。
# 6.2.3.5.partitionKey
可选元素
field元素的容器,用于指定Cassandra的分区键。
定义了Ignite缓存的键对象字段(在它里面),它会被用作Cassandra表的分区键,并且指定了到表列的字段映射。
映射是通过<field>标签设定的,它有如下的属性:
| 属性 | 必需 | 描述 |
|---|---|---|
name | 是 | POJO对象字段名 |
column | 否 | Cassandra表列名,如果不指定,会使用POJO字段名的小写形式 |
# 6.2.3.6.clusterKey
可选元素
field元素的容器,用于指定Cassandra的集群键。
定义了Ignite缓存的键对象字段(在它里面),它会被用作Cassandra表的集群键,并且指定了到表列的字段映射。
映射是通过<field>标签设定的,它有如下的属性:
| 属性 | 必需 | 描述 |
|---|---|---|
name | 是 | POJO对象字段名 |
column | 否 | Cassandra表列名,如果不指定,会使用POJO字段名的小写形式 |
sort | 否 | 指定字段排序规则(asc或者desc) |
# 6.2.3.7.valuePersistence
必要元素
Ignite缓存值的持久化配置。
这些设置指定了Ignite缓存的值对象如何存储/加载到/从Cassandra表,这些设置的属性看上去和对应的Ignite缓存键的设定很像。
| 属性 | 必需 | 描述 |
|---|---|---|
class | 是 | Ignite缓存值的Java类名。 |
strategy | 是 | 指定三个可能的持久化策略之一(看下面的描述),它会控制对象如何存储/加载到/从Cassandra表。 |
serializer | 否 | BLOB策略的序列化器类(可用的实现看下面),PRIMITIVE和POJO策略时无法使用。 |
column | 否 | PRIMITIVE和BLOB策略时存储值的列名,如果不指定,列名为value,对于POJO策略属性无需指定。 |
持久化策略(与键的持久化策略一致):
| 名称 | 描述 |
|---|---|
PRIMITIVE | 存储对象,通过对应的类型将其映射到Cassandra表列中,只能使用简单的Java类型(int、long、String、double、Date),它们会直接映射到对应的Cassandra类型上,要了解详细的Java到Cassandra的类型映射,点击这里。 |
BLOB | 将对象存储为BLOB,使用BLOB类型将其映射到Cassandra表列,可以使用任何Java对象,Java对象到BLOB的转换是由valuePersistence容器中的serializer属性指定的序列化器处理的。 |
POJO | 将对象的每个属性按照对应的类型存储到Cassandra的表中,对于对象的属性,提供了利用Cassandra二级索引的能力,只能用于遵守Java Bean规范的POJO对象,并且它的属性都是基本Java类型,它们会直接映射到对应的Cassandra类型上。 |
可用的序列化器实现
| 类名 | 描述 |
|---|---|
| org.apache.ignite.cache.store.cassandra.utils.serializer.JavaSerializer | 使用标准的Java序列化框架 |
| org.apache.ignite.cache.store.cassandra.utils.serializer.KryoSerializer | 使用Kryo序列化框架 |
如果使用了PRIMITIVE和BLOB持久化策略,那么是不需要指定valuePersistence标签的内部元素的,这样的原因是,这两个策略中整个对象都被持久化到Cassandra表中的一列(可以通过column指定)。
如果使用POJO持久化策略,那么有两个策略:
- 让
valuePersistence标签为空,这时,POJO对象类的所有字段都会通过如下的规则自动检测:- 只有那些可以直接映射到对应的Cassandra类型的简单Java类型会被自动检测;
- 字段的发现机制会考虑
@QuerySqlField注解;- 如果指定了
name属性,它会被用作Cassandra表中的列名,否则属性名的小写形式会被用做列名; - 如果指定了
index属性,会在Cassandra表中为相应的列创建二级索引(如果这样的表不存在)。
- 如果指定了
- 在
valuePersistence标签中指定持久化的细节,这时,就需要在valuePersistence标签中指定POJO字段到Cassandra表列的映射。
如果选择了上述的第二个选项,那么需要使用<field>标签指定POJO字段到Cassandra表列的映射,这个标签有如下的属性:
| 属性 | 必需 | 描述 |
|---|---|---|
name | 是 | POJO对象字段名 |
column | 否 | Cassandra表列名,如果不指定,会使用POJO字段名的小写形式 |
static | 否 | 布尔类型标志,它指定了在一个分区内列是否为静态的 |
index | 否 | 布尔类型标志,指定了对于某字段是否要创建二级索引 |
indexClass | 否 | 如果要使用自定义索引,自定义索引的Java类名 |
indexOptions | 否 | 自定义索引选项 |
# 6.3.示例
# 6.3.1.概述
就像上一章描述的那样,要将Cassandra配置为缓存存储,需要将Ignite缓存的CacheStoreFactory设置为org.apache.ignite.cache.store.cassandra.CassandraCacheStoreFactory。
下面是一个Ignite将Cassandra配置为缓存存储的典型配置示例,即使它看上去很复杂也不用担心,后续会一步一步深入每一个配置项,这个示例来自于Cassandra模块源代码的单元测试资源文件test/resources/org/apache/ignite/tests/persistence/blob/ignite-config.xml。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<!-- Cassandra connection settings -->
<import resource="classpath:org/apache/ignite/tests/cassandra/connection-settings.xml" />
<!-- Persistence settings for 'cache1' -->
<bean id="cache1_persistence_settings" class="org.apache.ignite.cache.store.cassandra.persistence.KeyValuePersistenceSettings">
<constructor-arg type="org.springframework.core.io.Resource" value="classpath:org/apache/ignite/tests/persistence/blob/persistence-settings-1.xml" />
</bean>
<!-- Persistence settings for 'cache2' -->
<bean id="cache2_persistence_settings" class="org.apache.ignite.cache.store.cassandra.persistence.KeyValuePersistenceSettings">
<constructor-arg type="org.springframework.core.io.Resource" value="classpath:org/apache/ignite/tests/persistence/blob/persistence-settings-3.xml" />
</bean>
<!-- Ignite configuration -->
<bean id="ignite.cfg" class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="cacheConfiguration">
<list>
<!-- Configuring persistence for "cache1" cache -->
<bean class="org.apache.ignite.configuration.CacheConfiguration">
<property name="name" value="cache1"/>
<property name="readThrough" value="true"/>
<property name="writeThrough" value="true"/>
<property name="cacheStoreFactory">
<bean class="org.apache.ignite.cache.store.cassandra.CassandraCacheStoreFactory">
<property name="dataSourceBean" value="cassandraAdminDataSource"/>
<property name="persistenceSettingsBean" value="cache1_persistence_settings"/>
</bean>
</property>
</bean>
<!-- Configuring persistence for "cache2" cache -->
<bean class="org.apache.ignite.configuration.CacheConfiguration">
<property name="name" value="cache2"/>
<property name="readThrough" value="true"/>
<property name="writeThrough" value="true"/>
<property name="cacheStoreFactory">
<bean class="org.apache.ignite.cache.store.cassandra.CassandraCacheStoreFactory">
<property name="dataSourceBean" value="cassandraAdminDataSource"/>
<property name="persistenceSettingsBean" value="cache2_persistence_settings"/>
</bean>
</property>
</bean>
</list>
</property>
<!-- Explicitly configure TCP discovery SPI to provide list of initial nodes. -->
<property name="discoverySpi">
<bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi">
<property name="ipFinder">
<!--
Ignite provides several options for automatic discovery that can be used
instead os static IP based discovery. For information on all options refer
to our documentation: https://ignite.apache.org/docs/latest/clustering/clustering
-->
<!-- Uncomment static IP finder to enable static-based discovery of initial nodes. -->
<!--<bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.vm.TcpDiscoveryVmIpFinder">-->
<bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.multicast.TcpDiscoveryMulticastIpFinder">
<property name="addresses">
<list>
<!-- In distributed environment, replace with actual host IP address. -->
<value>127.0.0.1:47500..47509</value>
</list>
</property>
</bean>
</property>
</bean>
</property>
</bean>
</beans>
在这个示例中,配置了两个Ignite缓存:cache1和cache2,下面会看配置的细节。
这两个缓存非常接近(cache1和cache2),看起来像这样:
<bean class="org.apache.ignite.configuration.CacheConfiguration">
<property name="name" value="cache1"/>
<property name="readThrough" value="true"/>
<property name="writeThrough" value="true"/>
<property name="cacheStoreFactory">
<bean class="org.apache.ignite.cache.store.cassandra.CassandraCacheStoreFactory">
<property name="dataSourceBean" value="cassandraAdminDataSource"/>
<property name="persistenceSettingsBean" value="cache1_persistence_settings"/>
</bean>
</property>
</bean>
首先可以看到通读和通写选项已经启用了:
<property name="readThrough" value="true"/>
<property name="writeThrough" value="true"/>
如果希望为过期条目使用持久化存储,这个对于Ignite缓存就是必要的。
如果希望异步更新持久化存储,也可以有选择地配置后写参数。
<property name="writeBehindEnabled" value="true"/>
下一个重要的事就是CacheStoreFactory的配置:
<property name="cacheStoreFactory">
<bean class="org.apache.ignite.cache.store.cassandra.CassandraCacheStoreFactory">
<property name="dataSourceBean" value="cassandraAdminDataSource"/>
<property name="persistenceSettingsBean" value="cache1_persistence_settings"/>
</bean>
</property>
可以看到将org.apache.ignite.cache.store.cassandra.CassandraCacheStoreFactory作为一个CacheStoreFactory,这使得Ignite缓存可以使用Cassandra作为持久化存储。对于CassandraCacheStoreFactory,需要指定两个必要的属性:
dataSourceBean:spring bean的名字,它指定了所有与Cassandra数据库连接有关的细节,要了解更多细节,可以看上一章的介绍;persistenceSettingsBean:spring bean的名字,它指定了对象如何持久化到Cassandra数据库的细节,要了解更多细节,可以看上一章的介绍。
在这个示例中,cassandraAdminDataSource是一个datasource bean,可以使用如下的指令导入Ignite的缓存配置文件:
<import resource="classpath:org/apache/ignite/tests/cassandra/connection-settings.xml" />
cache1_persistence_settings是一个持久化配置bean,它是在Ignite缓存配置文件中使用如下的方式配置的:
<bean id="cache1_persistence_settings" class="org.apache.ignite.cache.store.cassandra.utils.persistence.KeyValuePersistenceSettings">
<constructor-arg type="org.springframework.core.io.Resource" value="classpath:org/apache/ignite/tests/persistence/blob/persistence-settings-1.xml" />
</bean>
现在可以从org/apache/ignite/tests/cassandra/connection-settings.xml测试资源文件中看一下cassandraAdminDataSource的设置。
具体来说,CassandraAdminCredentials和CassandraRegularCredentials类都是org.apache.ignite.cache.store.cassandra.datasource.Credentials的扩展,也可以自定义然后引用它们。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="cassandraAdminCredentials" class="org.apache.ignite.tests.utils.CassandraAdminCredentials"/>
<bean id="loadBalancingPolicy" class="com.datastax.driver.core.policies.RoundRobinPolicy"/>
<bean id="contactPoints" class="org.apache.ignite.tests.utils.CassandraHelper" factory-method="getContactPointsArray"/>
<bean id="cassandraAdminDataSource" class="org.apache.ignite.cache.store.cassandra.utils.datasource.DataSource">
<property name="credentials" ref="cassandraAdminCredentials"/>
<property name="contactPoints" ref="contactPoints"/>
<property name="readConsistency" value="ONE"/>
<property name="writeConsistency" value="ONE"/>
<property name="loadBalancingPolicy" ref="loadBalancingPolicy"/>
</bean>
</beans>
有关Cassandra数据源连接配置的更多详细信息,请参见配置章节的介绍。
最后,还没有描述的最后一个片段就是持久化设置的配置,可以从org/apache/ignite/tests/persistence/blob/persistence-settings-1.xml测试资源文件中看一下cache1_persistence_settings:
<persistence keyspace="test1" table="blob_test1">
<keyPersistence class="java.lang.Integer" strategy="PRIMITIVE" />
<valuePersistence strategy="BLOB"/>
</persistence>
在这个配置中,可以看到Cassandra的test1.blob_test1表会用于cache1缓存的键/值存储,缓存的键对象会以integer的形式存储于key列中,缓存的值对象会以blob的形式存储于value列中。
下一章会为不同类型的持久化策略提供持久化设置的示例。
# 6.3.2.示例1
Ignite缓存的持久化配置中,Integer类型的键在Cassandra中会以int的形式存储,String类型的值在Cassandra中会以text的形式存储。
<persistence keyspace="test1" table="my_table">
<keyPersistence class="java.lang.Integer" strategy="PRIMITIVE" column="my_key"/>
<valuePersistence class="java.lang.String" strategy="PRIMITIVE" />
</persistence>
键会存储于my_key列,值会存储于value列(如果column属性不指定会使用默认值)。
# 6.3.3.示例2
Ignite缓存的持久化配置中,Integer类型的键在Cassandra中会以int的形式存储,any类型的值(BLOB持久化策略中无需指定类型)在Cassandra中会以BLOB的形式存储,这个场景的唯一解决方案就是在Cassandra中将值存储为BLOB。
<persistence keyspace="test1" table="my_table">
<keyPersistence class="java.lang.Integer" strategy="PRIMITIVE" />
<valuePersistence strategy="BLOB"/>
</persistence>
键会存储于key列(如果column属性不指定会使用默认值),值会存储于value列。
# 6.3.4.示例3
Ignite缓存的持久化配置中,Integer类型的键和any类型的值在Cassandra中都以BLOB的形式存储。
<persistence keyspace="test1" table="my_table">
<!-- By default Java standard serialization is going to be used -->
<keyPersistence class="java.lang.Integer"
strategy="BLOB"/>
<!-- Kryo serialization specified to be used -->
<valuePersistence class="org.apache.ignite.tests.pojos.Person"
strategy="BLOB"
serializer="org.apache.ignite.cache.store.cassandra.utils.serializer.KryoSerializer"/>
</persistence>
键会存储于BLOB类型的key列,使用Java标准序列化,值会存储于BLOB类型的value列,使用Kryo序列化。
# 6.3.5.示例4
Ignite缓存的持久化配置中,Integer类型的键在Cassandra中会以int的形式存储,自定义POJOorg.apache.ignite.tests.pojos.Person类型的值在动态分析后会被持久化到一组表列中,这样每个POJO字段都会被映射到相对应的表列,关于更多动态POJO字段发现的信息,可以查看上一章的介绍。
<persistence keyspace="test1" table="my_table">
<keyPersistence class="java.lang.Integer" strategy="PRIMITIVE"/>
<valuePersistence class="org.apache.ignite.tests.pojos.Person" strategy="POJO"/>
</persistence>
键会存储于int类型的key列。
假设org.apache.ignite.tests.pojos.Person类的实现如下:
public class Person {
private String firstName;
private String lastName;
private int age;
private boolean married;
private long height;
private float weight;
private Date birthDate;
private List<String> phones;
public void setFirstName(String name) {
firstName = name;
}
public String getFirstName() {
return firstName;
}
public void setLastName(String name) {
lastName = name;
}
public String getLastName() {
return lastName;
}
public void setAge(int age) {
this.age = age;
}
public int getAge() {
return age;
}
public void setMarried(boolean married) {
this.married = married;
}
public boolean getMarried() {
return married;
}
public void setHeight(long height) {
this.height = height;
}
public long getHeight() {
return height;
}
public void setWeight(float weight) {
this.weight = weight;
}
public float getWeight() {
return weight;
}
public void setBirthDate(Date date) {
birthDate = date;
}
public Date getBirthDate() {
return birthDate;
}
public void setPhones(List<String> phones) {
this.phones = phones;
}
public List<String> getPhones() {
return phones;
}
}
这时,Ignite缓存中org.apache.ignite.tests.pojos.Person类型的值会使用如下的动态配置映射规则持久化到一组Cassandra表列中:
| POJO字段 | 表列 | 列类型 |
|---|---|---|
| firstName | firstname | text |
| lastName | lastname | text |
| age | age | int |
| married | married | boolean |
| height | height | bigint |
| weight | weight | float |
| birthDate | birthdate | timestamp |
从上表可以看出,phones字段不会被持久化到表中,这是应为它不是一个可以映射到对应Cassandra类型的简单Java类型,这种类型的字段只有在给这个对象类型手工指定所有的映射细节以及字段类型本身实现了java.io.Serializable接口时才会被持久化于Cassandra中。这时,字段会被持久化到一个单独的BLOB类型的表列。下个示例会看到更多的细节。
# 6.3.6.示例5
Ignite缓存的持久化配置中,键是自定义的POJOorg.apache.ignite.tests.pojos.PersonId类型,值是自定义POJOorg.apache.ignite.tests.pojos.Person类型,基于手工指定的映射规则,都会被持久化到一组表列。
<persistence keyspace="test1" table="my_table" ttl="86400">
<!-- Cassandra keyspace options which should be used to create provided keyspace if it doesn't exist -->
<keyspaceOptions>
REPLICATION = {'class' : 'SimpleStrategy', 'replication_factor' : 3}
AND DURABLE_WRITES = true
</keyspaceOptions>
<!-- Cassandra table options which should be used to create provided table if it doesn't exist -->
<tableOptions>
comment = 'A most excellent and useful table'
AND read_repair_chance = 0.2
</tableOptions>
<!-- Persistent settings for Ignite cache keys -->
<keyPersistence class="org.apache.ignite.tests.pojos.PersonId" strategy="POJO">
<!-- Partition key fields if POJO strategy used -->
<partitionKey>
<!-- Mapping from POJO field to Cassandra table column -->
<field name="companyCode" column="company" />
<field name="departmentCode" column="department" />
</partitionKey>
<!-- Cluster key fields if POJO strategy used -->
<clusterKey>
<!-- Mapping from POJO field to Cassandra table column -->
<field name="personNumber" column="number" sort="desc"/>
</clusterKey>
</keyPersistence>
<!-- Persistent settings for Ignite cache values -->
<valuePersistence class="org.apache.ignite.tests.pojos.Person"
strategy="POJO"
serializer="org.apache.ignite.cache.store.cassandra.utils.serializer.KryoSerializer">
<!-- Mapping from POJO field to Cassandra table column -->
<field name="firstName" column="first_name" />
<field name="lastName" column="last_name" />
<field name="age" />
<field name="married" index="true"/>
<field name="height" />
<field name="weight" />
<field name="birthDate" column="birth_date" />
<field name="phones" />
</valuePersistence>
</persistence>
这些配置看上去非常复杂,下面会一步一步地分析。
首先看一下根标签:
<persistence keyspace="test1" table="my_table" ttl="86400">
它指定了Ignite缓存的键和值应该存储于test1.my_table表,并且每一条数据会在86400秒(24小时)后过期。
然后可以看到关于Cassandra键空间的高级配置,在不存在时,这个配置会用于创建键空间。
<keyspaceOptions>
REPLICATION = {'class' : 'SimpleStrategy', 'replication_factor' : 3}
AND DURABLE_WRITES = true
</keyspaceOptions>
然后通过对键空间配置的分析,可以看到只会用于表创建的高级配置。
<tableOptions>
comment = 'A most excellent and useful table'
AND read_repair_chance = 0.2
</tableOptions>
下一个章节说明了Ignite缓存的键如何持久化:
<keyPersistence class="org.apache.ignite.tests.pojos.PersonId" strategy="POJO">
<!-- Partition key fields if POJO strategy used -->
<partitionKey>
<!-- Mapping from POJO field to Cassandra table column -->
<field name="companyCode" column="company" />
<field name="departmentCode" column="department" />
</partitionKey>
<!-- Cluster key fields if POJO strategy used -->
<clusterKey>
<!-- Mapping from POJO field to Cassandra table column -->
<field name="personNumber" column="number" sort="desc"/>
</clusterKey>
</keyPersistence>
假定org.apache.ignite.tests.pojos.PersonId的实现如下:
public class PersonId {
private String companyCode;
private String departmentCode;
private int personNumber;
public void setCompanyCode(String code) {
companyCode = code;
}
public String getCompanyCode() {
return companyCode;
}
public void setDepartmentCode(String code) {
departmentCode = code;
}
public String getDepartmentCode() {
return departmentCode;
}
public void setPersonNumber(int number) {
personNumber = number;
}
public int getPersonNumber() {
return personNumber;
}
}
这时Ignite缓存中org.apache.ignite.tests.pojos.PersonId类型的键会使用如下的映射规则持久化到一组表示分区和集群键的Cassandra表列:
| POJO字段 | 表列 | 列类型 |
|---|---|---|
| companyCode | company | text |
| departmentCode | department | text |
| personNumber | number | int |
另外,(company, department)的列组合会用作为Cassandra的PARTITION键,number列会用作为倒序排列的集群键。
最后到最后一章,它指定了Ignite缓存值的持久化配置:
<valuePersistence class="org.apache.ignite.tests.pojos.Person"
strategy="POJO"
serializer="org.apache.ignite.cache.store.cassandra.utils.serializer.KryoSerializer">
<!-- Mapping from POJO field to Cassandra table column -->
<field name="firstName" column="first_name" />
<field name="lastName" column="last_name" />
<field name="age" />
<field name="married" index="true"/>
<field name="height" />
<field name="weight" />
<field name="birthDate" column="birth_date" />
<field name="phones" />
</valuePersistence>
假定org.apache.ignite.tests.pojos.Person类和示例4的实现一样,这时Ignite缓存的org.apache.ignite.tests.pojos.Person类型的值会以如下的映射规则持久化到一组Cassandra表列:
| POJO字段 | 表列 | 列类型 |
|---|---|---|
| firstName | first_name | text |
| lastName | last_name | text |
| age | age | int |
| married | married | boolean |
| height | height | bigint |
| weight | weight | float |
| birthDate | birth_date | timestamp |
| phones | phones | blob |
和示例4相比,可以看到,使用Kryo序列化器,phones字段会被序列化到blob类型的phones列。另外Cassandra会为married列创建二级索引。
# 6.4.DDL生成器
# 6.4.1.概述
Ignite Cassandra模块的一个好处是,无需关注Cassandra的表创建DDL语法以及Java到Cassandra的类型映射细节。
只需要创建指定了Ignite缓存的键和值如何序列化/反序列化到/从Cassandra的XML配置文档即可,基于这个设置,剩余的Cassandra键空间和表都会被自动创建,要让这一切运转起来,只需要:
警告
在Cassandra的连接设置中,指定的用户要有足够的权限来创建键空间和表。
不过因为严格的安全策略,某些环境中这是不可能的。这个场景的唯一解决方案就是向运维团队提供DDL脚本来创建所有必要的Cassandra键空间和表。
这就是使用DDL生成工具的确切场景,它会从一个持久化配置中生成DDL。
下面是Cassandra中DDL生成的语法样例:
java org.apache.ignite.cache.store.cassandra.utils.DDLGenerator /opt/dev/ignite/persistence-settings-1.xml /opt/dev/ignite/persistence-settings-2.xml
生成的DDL大体如下:
-------------------------------------------------------------
DDL for keyspace/table from file: /opt/dev/ignite/persistence-settings-1.xml
-------------------------------------------------------------
create keyspace if not exists test1
with replication = {'class' : 'SimpleStrategy', 'replication_factor' : 3} and durable_writes = true;
create table if not exists test1.primitive_test1
(
key int,
value int,
primary key ((key))
);
-------------------------------------------------------------
DDL for keyspace/table from file: /opt/dev/ignite/persistence-settings-2.xml
-------------------------------------------------------------
create keyspace if not exists test1
with REPLICATION = {'class' : 'SimpleStrategy', 'replication_factor' : 3} AND DURABLE_WRITES = true;
create table if not exists test1.pojo_test3
(
company text,
department text,
number int,
first_name text,
last_name text,
age int,
married boolean,
height bigint,
weight float,
birth_date timestamp,
phones blob,
primary key ((company, department), number)
)
with comment = 'A most excellent and useful table' AND read_repair_chance = 0.2 and clustering order by (number desc);
不要忘了设置正确的CLASSPATH环境变量:
- 在CLASSPATH中包含Ignite Cassandra模块的jar文件(
ignite-cassandra-<version-number>.jar); - 如果打算为部分自定义Java类使用
POJO持久化策略,需要同时在CLASSPATH中包含带有这些类的jar文件。
# 7.PHP PDO
# 7.1.概述
PHP提供了一个轻量级、一致的接口来访问数据库,叫做PHP数据对象-PDO,这个扩展依赖于数据库的PDO驱动,其中之一是PDO_ODBC,它可以接入任何实现了自己的ODBC驱动的数据库。
通过使用Ignite的ODBC驱动,从PHP应用中就可以接入Ignite集群,然后访问和修改数据,本章节就会介绍如何达到该目的。
# 7.2.配置ODBC驱动
Ignite遵守ODBC协议,并且实现了自己的ODBC驱动,这个驱动会用于PHP的PDO框架接入Ignite集群。
查看本系列文档的ODBC部分,可以知道如何在目标系统上安装和配置这个驱动,安装完毕后,就可以进入下一个章节。
# 7.3.安装和配置PHP PDO
要安装PHP,PDO以及PDO_ODBC驱动,可以看PHP的相关资源。
- 下载并安装期望的版本,注意,在PHP的5.1.0版本中,默认开启了PDO驱动,在Windows环境下,可以从这里下载PHP的二进制包;
- 配置PHP的PDO框架;
- 启用PDO_ODBC驱动:
- 在Windows中,需要在php.ini文件中将
extension=php_pdo_odbc.dll的注释去掉,并且确保extension_dir指向php_pdo_odbc.dll所在的目录,另外,这个目录还需要加入PATH环境变量; - 在类Unix系统中,通常可能只需要简单地安装某PHP_ODBC包,比如,Ubuntu14.04中已经安装了
php5-odbc;
- 在Windows中,需要在php.ini文件中将
- 如果必要,在一些特定的系统中,无法按照常规方法配置和构建PDO_ODBC驱动,但是大多数情况下,简单地安装PHP和PDO_ODBC驱动就可以了。
# 7.4.启动Ignite集群
PHP PDO准备就绪之后,就可以通过一个常规的配置启动Ignite集群,然后在PHP应用中接入集群并且查询和修改集群的数据。
- 首先,集群端已经启用了ODBC处理器,即在每个集群节点的
IgniteConfiguration中都加入了odbcConfiguration; - 下一步,列出
IgniteConfiguration中与特定数据模型有关的所有缓存的配置,因为之后要在PHP PDO端执行SQL查询,所有每个缓存的配置都需要包含一个QueryEntity的定义,或者也可以使用Ignite的DDL命令来定义SQL表和索引; - 最后,可以使用下面的配置模板启动一个Ignite集群:
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:util="http://www.springframework.org/schema/util" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/util http://www.springframework.org/schema/util/spring-util.xsd"> <bean id="ignite.cfg" class="org.apache.ignite.configuration.IgniteConfiguration"> <!-- Enabling ODBC. --> <property name="odbcConfiguration"> <bean class="org.apache.ignite.configuration.OdbcConfiguration"></bean> </property> <!-- Configuring cache. --> <property name="cacheConfiguration"> <list> <bean class="org.apache.ignite.configuration.CacheConfiguration"> <property name="name" value="Person"/> <property name="cacheMode" value="PARTITIONED"/> <property name="atomicityMode" value="TRANSACTIONAL"/> <property name="writeSynchronizationMode" value="FULL_SYNC"/> <property name="queryEntities"> <list> <bean class="org.apache.ignite.cache.QueryEntity"> <property name="keyType" value="java.lang.Long"/> <property name="valueType" value="Person"/> <property name="fields"> <map> <entry key="firstName" value="java.lang.String"/> <entry key="lastName" value="java.lang.String"/> <entry key="resume" value="java.lang.String"/> <entry key="salary" value="java.lang.Integer"/> </map> </property> <property name="indexes"> <list> <bean class="org.apache.ignite.cache.QueryIndex"> <constructor-arg value="salary"/> </bean> </list> </property> </bean> </list> </property> </bean> </list> </property> </bean> </beans>
# 7.5.从PHP端接入Ignite集群
要从PHP PDO端接入Ignite,需要正确地配置DSN。
在下面的示例中,假定DSN名为LocalApacheIgniteDSN。都配置好之后,PHP PDO应用就可以接入Ignite集群了,可以像下面这样执行一些查询:
# 8.性能统计
# 8.1.概述
Ignite内置了用于分析集群的工具,该扩展可以从集群中收集性能统计然后生成性能报告以及输出统计信息。
# 8.2.生成报告
Ignite提供了一个工具,可以从性能统计文件生成报告。
下面是生成性能报告的步骤:
- 停止收集统计信息,然后将所有节点的统计文件放入一个空文件夹,比如:
/path_to_files/ ├── node-162c7147-fef8-4ea2-bd25-8653c41fc7fa.prf ├── node-7b8a7c5c-f3b7-46c3-90da-e66103c00001.prf └── node-faedc6c9-3542-4610-ae10-4ff7e0600000.prf - 从该工具的二进制包中执行下面的脚本:
performance-statistics-tool/build-report.sh path_to_files
然后会在path_to_files/report_yyyy-MM-dd_HH-mm-ss/这个目录中生成性能统计报告,在浏览器中打开report_yyyy-MM-dd_HH-mm-ss/index.html,就可以查看报告。
更多的细节可以查看help命令:
performance-statistics-tool/build-report.sh --help
# 8.2.1.性能统计报告示例
- 缓存操作:

- 事务

- 查询
- 计算
- 集群信息

# 8.3.输出统计信息
Ignite还提供一个工具,可以将统计信息输出到控制台,或者一个JSON格式的文件。
从该工具的二进制包中执行下面的脚本:
performance-statistics-tool/print-statistics.sh path_to_files
这里path_to_files是性能统计文件的路径或者文件夹。
该脚本可以通过操作类型、时间或者缓存对操作进行过滤,跟多的细节可以查看help命令:
performance-statistics-tool/print-statistics.sh --help
输出大致如下:
{"op":"CACHE_GET","nodeId":"955130d1-5218-4e46-87f6-62755e92e9b4","cacheId":-1809642915,"startTime":1616837094237,"duration":64992213}
{"op":"CACHE_PUT","nodeId":"955130d1-5218-4e46-87f6-62755e92e9b4","cacheId":-1809642915,"startTime":1616837094237,"duration":879869}
{"op":"CACHE_GET_AND_PUT","nodeId":"955130d1-5218-4e46-87f6-62755e92e9b4","cacheId":1328364293,"startTime":1616837094248,"duration":17186240}
{"op":"TX_COMMIT","nodeId":"955130d1-5218-4e46-87f6-62755e92e9b4","cacheIds":[-1809642915],"startTime":1616837094172,"duration":184887787}
{"op":"QUERY","nodeId":"955130d1-5218-4e46-87f6-62755e92e9b4","type":"SQL_FIELDS","text":"create table Person (id int, val varchar, primary key (id))","id":0,"startTime":1616837094143,"duration":258741595,"success":true}
# 9.变更数据捕获
警告
CDC是一个试验性的特性,API和设计架构可能发生变更。
# 9.1.概述
CDC扩展模块提供3种方式来进行基于CDC的跨集群数据复制。
- Ignite2IgniteClientCdcStreamer:使用Java瘦客户端将变更写入目标端集群;
- Ignite2IgniteCdcStreamer:使用客户端节点将变更流式写入目标端集群;
- Ignite2KafkaCdcStreamer:使用Apache Kafka作为媒介,与KafkaToIgniteCdcStreamer结合使用,将变更流式写入目标端集群。
注意
对于在集群间进行复制的每个缓存,需要定义CacheVersionConflictResolver。
注意
CDC复制的所有实现都支持BinaryTypes和TypeMappings的复制。
注意
要在目标端集群上对CDC复制的数据使用SQL查询,需要在CREATE TABLE中为每个表的源端集群和目标端集群设置相同的VALUE_TYPE。
# 9.2.Ignite到Java瘦客户端CDC流处理器
该流处理器会启动一个接入目标端集群的Java瘦客户端,连接建立之后,CDC捕获的数据变更都会被复制到目标端集群。
提示
配置好流处理器的ignite-cdc.sh,应在源端集群的每个服务端节点上启动,以捕获所有的数据变更。

# 9.2.1.配置
| 参数名 | 描述 | 默认值 |
|---|---|---|
caches | 要复制的缓存名集合 | null |
destinationClientConfiguration | 要接入目标端集群的瘦客户端的客户端配置 | null |
onlyPrimary | 只处理主节点数据变更的标志 | false |
maxBatchSize | 发给目标端集群每个批次的最大事件数 | 1024 |
# 9.2.2.指标
| 指标名 | 描述 |
|---|---|
EventsCount | 发给目标端集群的消息数 |
LastEventTime | 上次发送事件的时间戳 |
TypesCount | 收到的二进制类型事件数 |
MappingsCount | 收到的映射事件数 |
# 9.3.Ignite到Ignite CDC流处理器
该流处理器会启动一个接入目标端集群的客户端节点,连接建立之后,CDC捕获的变更数据就会被复制到目标端集群。
注意
配置了流处理器的ignite-cdc.sh实例,应在源端集群的每个服务端节点上启动,以便捕获所有的数据变更。

# 9.3.1.配置
| 属性名 | 描述 | 默认值 |
|---|---|---|
caches | 要复制的缓存名集合 | null |
destinationIgniteConfiguration | 要接入目标端集群复制变更数据的客户端节点的Ignite配置 | null |
onlyPrimary | 只处理主分区数据变更的标志 | false |
maxBatchSize | 在一个批次中发送到目标端集群的事件数量 | 1024 |
# 9.3.2.指标
| 指标名 | 描述 |
|---|---|
EventsCount | 发给目标端集群的消息数 |
LastEventTime | 上次发送事件的时间戳 |
TypesCount | 收到的二进制类型事件数 |
MappingsCount | 收到的映射事件数 |
# 9.4.使用Kafka进行CDC数据复制
这种在集群间复制数据变更的方式,需要启动两个应用:
- 使用
org.apache.ignite.cdc.kafka.IgniteToKafkaCdcStreamer的ignite-cdc.sh,它会从源端集群捕获变更数据然后将其写入Kafka主题; kafka-to-ignite.sh会从Kafka主题读取数据变更然后将其写入目标端集群。
注意
配置了流处理器的ignite-cdc.sh实例,应在源端集群的每个服务端节点上启动,以便捕获所有的数据变更。
注意
通过Kafka执行CDC为了保证顺序,需要metadata主题只有一个分区。

# 9.4.1.配置
| 属性名 | 描述 | 默认值 |
|---|---|---|
caches | 要复制的缓存名集合 | null |
kafkaProperties | Kafka生产者属性 | null |
topic | CDC事件的Kafka主题名 | null |
kafkaParts | CDC事件主题的Kafka分区数 | null |
metadataTopic | 用于复制BinaryTypes和TypeMappings的元数据主题名 | null |
onlyPrimary | 只处理主分区数据变更的标志 | false |
maxBatchSize | 在一个批次中发送到目标端集群的事件数量 | 1024 |
kafkaRequestTimeout | Kafka请求超时时间(毫秒) | 3000 |
# 9.4.2.指标
| 指标名 | 描述 |
|---|---|
EventsCount | 发到目标端集群的消息数量 |
LastEventTime | 上次发送事件的时间戳 |
BytesSent | 发给Kafka的字节数 |
# 9.4.3.kafka-to-ignite.sh应用
该应用应该在目标端集群侧启动,kafka-to-ignite.sh会从Kafka主题中读取CDC事件,然后将其写入目标端集群。
警告
kafka-to-ignite.sh实现了快速失败机制,任何错误都会导致失败。
该应用的实例数无需匹配目标端集群的服务端节点数量,只需要足已处理源端的负载即可。应用的每个实例会处理配置好的主题分区的子集来均衡负载,每个分区都会创建KafkaConsumer以确保公平读取。
安装
- 使用Maven来构建
cdc-ext模块;
$~/src/ignite-extensions/> mvn clean package -DskipTests
$~/src/ignite-extensions/> ls modules/cdc-ext/target | grep zip ignite-cdc-ext.zip
- 解压
ignite-cdc-ext.zip到$IGNITE_HOME文件夹。
现在,已经有了$IGNITE_HOME/bin/kafka-to-ignite.sh脚本和$IGNITE_HOME/libs/optional/ignite-cdc-ext模块。
注意
需要启用ignite-cdc-ext模块,以便kafka-to-ignite.sh可以运行。
配置
应用的配置应使用POJO类或者Spring的XML配置文件,就像常规的Ignite节点配置那样。Kafka到Ignite的配置文件应包含下面的配置,这些配置会在启动过程中加载:
需要配置一个下面的配置Bean,以定义接入目标端集群的客户端类型;
IgniteConfiguration:接入目标端集群的客户端节点配置;ClientConfiguration:Java瘦客户端配置。
名为
kafkaProperties的java.util.Properties:单个Kafka消费者配置;org.apache.ignite.cdc.kafka.KafkaToIgniteCdcStreamerConfiguration:kafka-to-ignite.sh应用的特定选项。
| 属性名 | 描述 | 默认值 |
|---|---|---|
caches | 要复制的缓存名集合 | null |
topic | 用于CDC事件的Kafka主题名 | null |
kafkaPartsFrom | 用于CDC事件的Kafka分区号起始值(包含) | -1 |
kafkaPartsTo | 用于CDC事件的Kafka分区号终止值(不包含) | -1 |
metadataTopic | 用于复制BinaryTypes和TypeMappings的元数据主题名 | null |
metadataConsumerGroup | 从元数据主题拉取数据的KafkaConsumer组 | ignite-metadata-update-<kafkaPartsFrom>-<kafkaPartsTo> |
kafkaRequestTimeout | Kafka请求超时时间(毫秒) | 3000 |
maxBatchSize | 在一个批次中发送到目标端集群的事件数量 | 1024 |
threadCount | 处理消费者的线程数,每个线程会以轮询的模式从特定分区拉取记录 | 16 |
日志
kafka-to-ignite.sh会与Ignite节点使用相同的日志配置,唯一的不同在于日志会被写入kafka-ignite-streamer.log文件。
# 9.5.CacheVersionConflictResolver实现
在多数实际环境中,为了容错,CDC流处理器都会将onlyPrimary配置为false,这意味着流处理器会将同一个变更事件发送多次,次数等同于CacheConfiguration中配置的副本数 + 1,这时复制集群就会收到同一个键的并发更新。Ignite节点会使用CacheVersionConflictResolver来对更新请求对应的数据条目进行筛选和合并,被选中的数据条目会被实际写入集群。
注意
默认的实现只会选择当前的条目,不会进行合并。
集群间复制的每个缓存,都要配置CacheVersionConflictResolver。
cdc-ext模块中定义了默认的实现。
# 9.5.1.配置
| 属性名 | 描述 | 默认值 |
|---|---|---|
clusterId | 本地集群ID,可以是1-31间的任意值 | null |
caches | 该插件实例要处理的缓存名集合 | null |
conflictResolveField | 解析冲突的值字段,可选,字段值必须实现java.lang.Comparable | null |
# 9.5.2.冲突解决算法
复制的变更包含了一些附加的数据,具体来说,变更数据中会包含源端集群的数据版本信息。默认的冲突解决算法会基于条目版本和conflictResolveField,冲突解决字段应包含用户提供的递增字段值,比如查询ID或者时间戳。
- 来自本地集群的变更总是会被选中;
- 如果来自同一集群的新旧条目版本相同,则会使用比较器来决定顺序;
- 如果提供了
conflictResolveField,则会对字段值进行比较来决定顺序; - 如果冲突解决失败,该更新会被忽略。
警告
当前的实现不支持在目标端集群的缓存上删除数据,数据必须在源端集群上删除。
# 9.5.3.配置示例
配置是Ignite插件的形式:
<property name="pluginProviders">
<bean class="org.apache.ignite.cdc.conflictresolve.CacheVersionConflictResolverPluginProvider">
<property name="clusterId" value="1" />
<property name="caches">
<util:list>
<bean class="java.lang.String">
<constructor-arg type="String" value="queryId" />
</bean>
</util:list>
</property>
</bean>
</property>
# 10.ZooKeeper IP探测器
提示
.NET/C#/C++目前还不支持。
Ignite的ZooKeeper IP探测器模块提供了一个基于ZooKeeper的TCP发现IP探测器实现,它会使用一个ZooKeeper目录来定位要接入的Ignite节点。
# 10.1.安装
根据使用Ignite的方式,可以在下面的方法中选一个开启该模块:
- 如果使用的是二进制发行版,可以在启动节点前,将
ignite-zookeeper-ip-finder-ext目录放入libs目录中; - 将
ignite-zookeeper-ip-finder-ext目录中的jar文件加入应用的类路径; - 在项目的Maven依赖中添加一个模块。
# 10.2.配置
要配置ZooKeeper IP探测器,需要使用TcpDiscoveryZookeeperIpFinder。
该模块依赖于使用SLF4J进行日志记录的第三方库,可以自己设置底层的日志框架。
18624049226
