# 数据建模
# 1.介绍
精心设计的数据模型可以提高应用的性能,高效地利用资源,并助力实现业务目标。在设计数据模型时,了解数据在Ignite集群中的分布方式以及访问数据的不同方式非常重要。
本章节会介绍Ignite数据分布模型的关键部分,包括分区和关联并置,以及用于访问数据的两个不同接口(键-值API和SQL)。
# 1.1.概述
为了了解数据在Ignite中的存储和使用,有必要区分集群中数据的物理组织和逻辑表示,即用户将如何在应用中查看其数据。
在物理层,每个数据条目(缓存条目或表数据行)都以二进制对象的形式存储,然后整个数据集被划分为多个较小的集合,称为分区。分区均匀地分布在所有节点上。数据和分区之间以及分区和节点之间的映射方式都由关联函数控制。
在逻辑层,数据应该以易于使用的方式表示,并方便用户在其应用中使用。Ignite提供了两种不同的数据逻辑表示:键-值缓存和SQL表(模式)。尽管这两种表示形式可能看起来有所不同,但实际上它们是等效的,并且可以表示同一组数据。
提示
注意,在Ignite中,SQL表和键-值缓存的概念是相同(内部)数据结构的两个等效表示,可以使用键-值API或SQL语句或同时使用两者来访问数据。
# 1.2.键-值缓存与SQL表
缓存是键-值对的集合,可以通过键-值API对其进行访问。Ignite中的SQL表与传统RDBMS中表的概念相对应,但有一些附加约束。例如每个SQL表必须有一个主键。
具有主键的表可以表示为键-值缓存,其中主键列用作键,其余的表列代表对象的字段(值)。
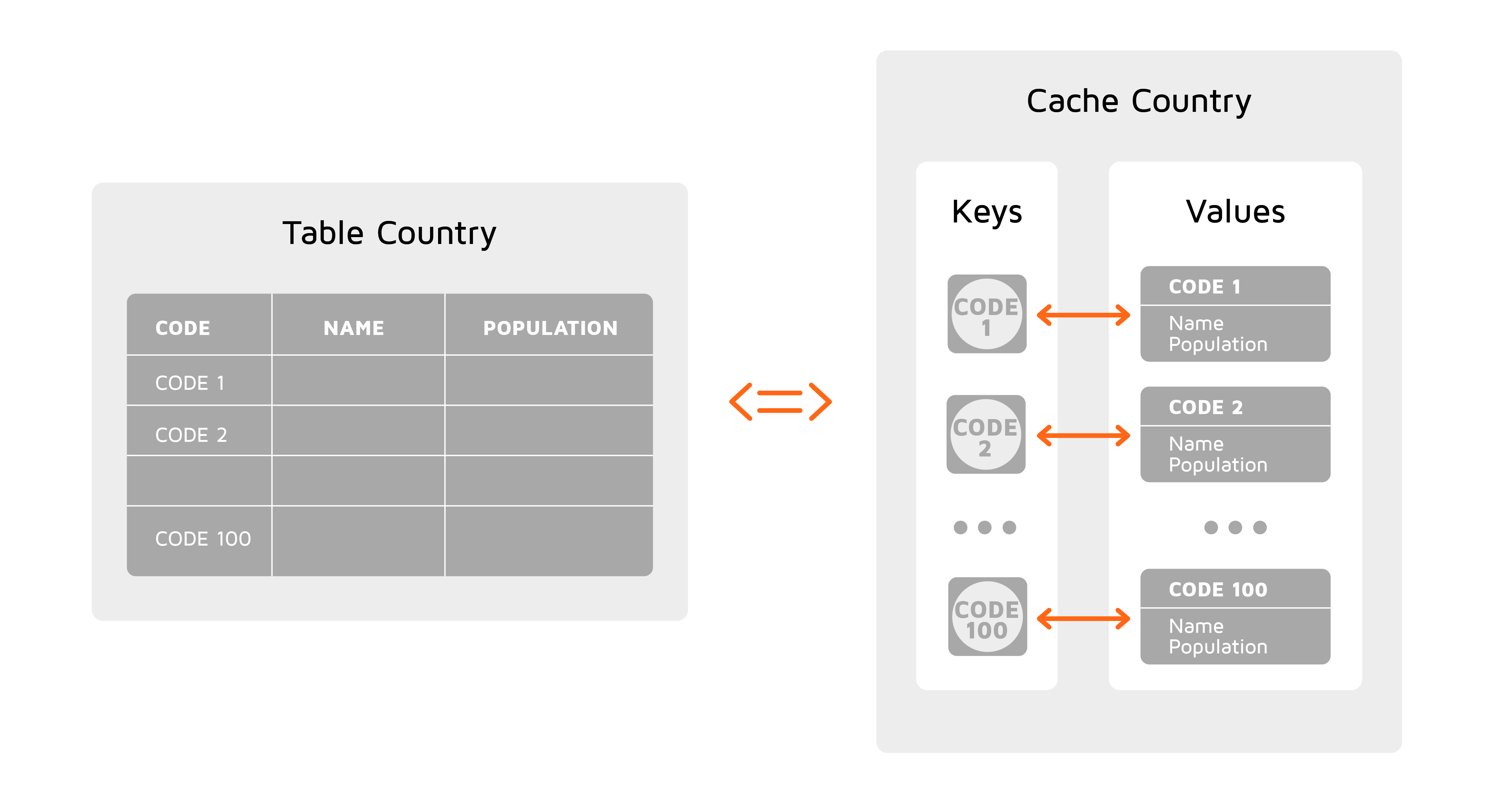
这两种表示形式之间的区别在于访问数据的方式。键-值缓存可以通过支持的编程语言来处理对象。SQL表支持传统的SQL语法,并且有助于从现有数据库进行迁移。开发者可以根据业务场景,灵活使用一种或两种方法。
缓存API支持以下功能:
- 支持JCache(JSR 107)规范;
- ACID事务;
- 持续查询;
- 事件。
提示
即使集群启动并运行后,也可以动态地创建键-值缓存和SQL表。
# 1.3.二进制对象格式
Ignite以称为二进制对象的特定格式存储数据条目,这种序列化格式具有以下优点:
- 可以从序列化的对象读取任意字段,而无需把对象完全反序列化,这完全消除了在服务端节点的类路径上部署键和值类的要求;
- 可以从相同类型的对象中添加或删除字段。考虑到服务端节点没有模型类的定义,此功能允许动态更改对象的结构,甚至允许多个客户端共存不同版本的类定义;
- 可以基于类型名称构造新对象,而完全不需要类定义,因此可以动态创建类型;
- 在Java、.NET和C++平台之间可以互操作。
仅当使用默认的二进制编组器(即在配置中未设置其他编组器)时,才可以使用二进制对象。
有关如何配置和使用二进制对象的更多信息,请参见使用二进制对象章节。
# 1.4.数据分区
数据分区是一种将大型数据集细分为较小的块,然后在所有服务端节点之间平均分配的方法。数据分区将在数据分区章节中详细介绍。
# 2.数据分区
数据分区是一种将大型数据集细分为较小的块,然后在所有服务端节点之间平均分配的方法。
分区由关联函数控制,关联函数确定键和分区之间的映射。每个分区由一组有限的数字(默认为0到1023)标识。分区集合分布在当前可用的服务端节点上。因此,每个键都会映射到某个节点,并存储在该节点上。当集群中节点的数量发生变化时,将通过称为再平衡的过程在新的节点集之间重新分配分区。
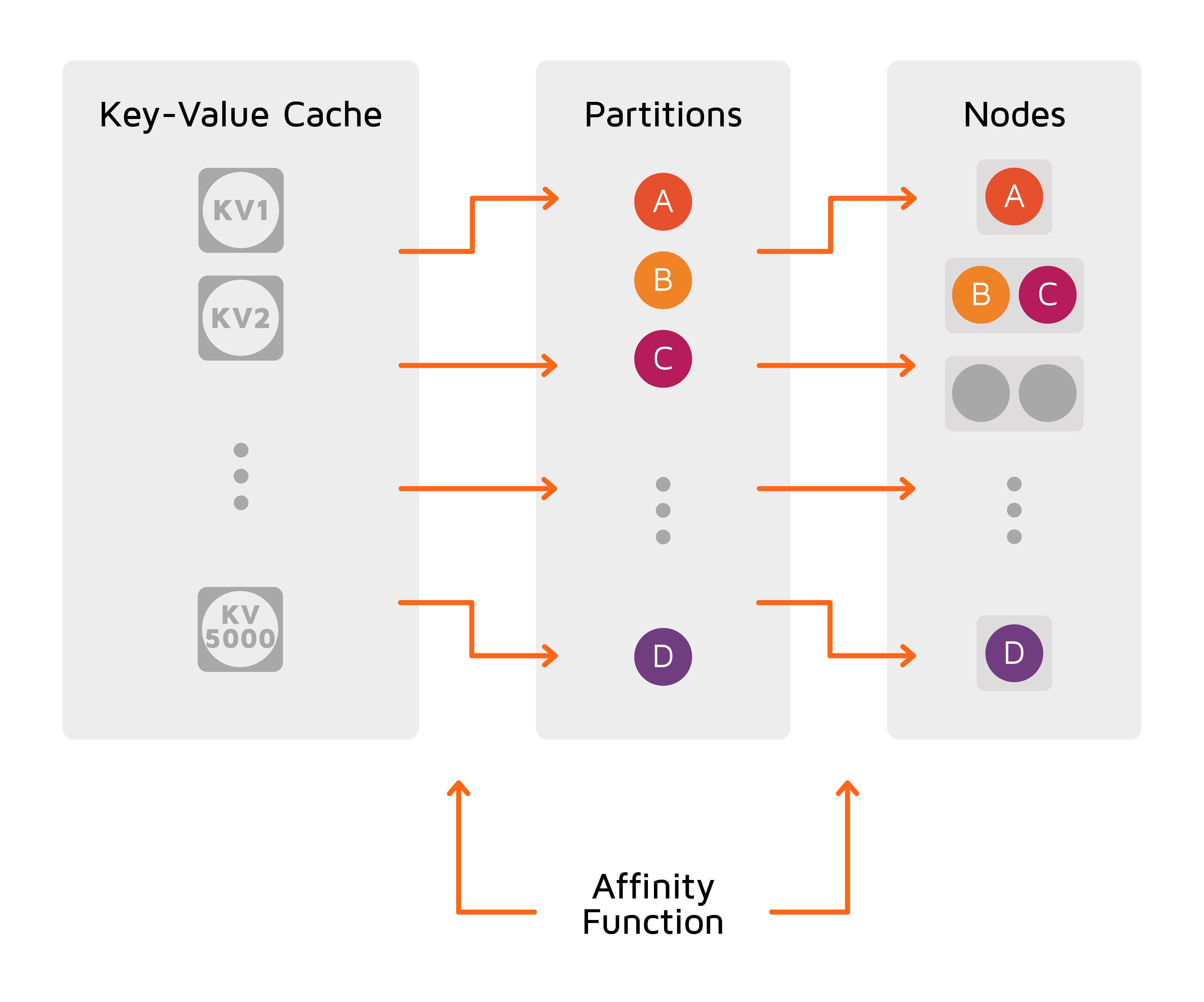
关联函数将关联键作为参数。关联键可以是缓存中存储的对象的任何字段(SQL表中的任何列)。如果未指定关联键,则默认使用键(对于SQL表,它是PRIMARY KEY列)。
提示
关于数据分区的更多信息,请参见Ignite数据分区深度解读。
分区通过将读写操作分布式化来提高性能。此外还可以设计数据模型,以使同一类数据条目存储在一起(即存储在一个分区中)。当请求该数据时,仅扫描少量分区,这种技术称为关联并置。
分区实际上可以在任何规模上实现线性可伸缩性。随着数据集的增长,可以向集群添加更多节点,Ignite会确保数据在所有节点间“平均”分布。
# 2.1.关联函数
关联函数控制数据条目和分区以及分区和节点之间的映射。默认的关联函数实现了约会哈希算法。它在分区到节点的映射中允许一些差异(即某些节点可能比其他节点持有的分区数量略多)。但是,关联函数可确保当拓扑更改时,分区仅迁移到新加入的节点或从离开的节点迁移,其余节点之间没有数据交换。
# 2.2.分区/复制模式
创建缓存或SQL表时,可以在缓存操作的分区模式和复制模式之间进行选择。两种模式设计用于不同的场景,并提供不同的性能和可用性优势。
# 2.2.1.PARTITIONED
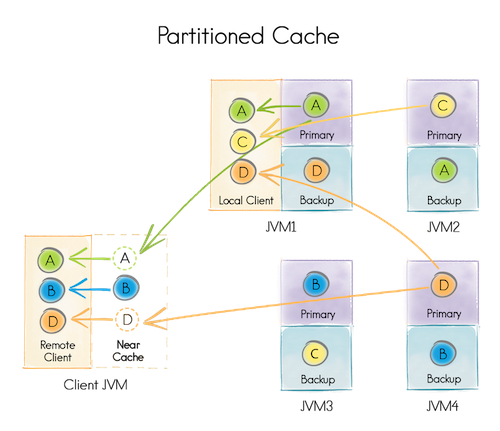
在这种模式下,所有分区在所有服务端节点间平均分配。此模式是可扩展性最高的分布式缓存模式,可以在所有节点上的总内存(RAM和磁盘)中存储尽可能多的数据,实际上节点越多,可以存储的数据就越多。
与REPLICATED模式不同,该模式下更新成本很高,因为集群中的每个节点都需要更新。而在PARTITIONED模式下,更新成本很低,因为每个键只需要更新一个主节点(以及可选的一个或多个备份节点)。但是读取成本会高,因为只有某些节点才缓存有该数据。
提示
当数据集很大且更新频繁时,分区缓存是理想的选择。
下图说明了分区缓存的分布,可以看出,将键A分配给在JVM1中运行的节点,将键B分配给在JVM3中运行的节点,等等。
# 2.2.2.REPLICATED
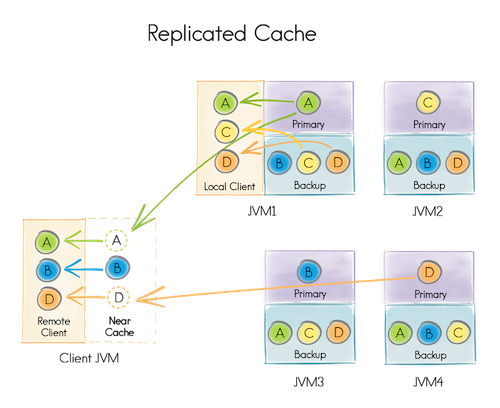
在REPLICATED模式下,所有数据(每个分区)都将复制到集群中的每个节点。由于每个节点上都有完整的数据,此缓存模式提供了最大的数据可用性。但是每次数据更新都必须传播到所有其他节点,这可能会影响性能和可扩展性。
提示
当数据集较小且不经常更新时,复制缓存非常理想。
在下图中,在JVM1中运行的节点是键A的主要节点,但它也存储了所有其他键(B,C,D)的备份副本。
因为相同的数据存储在所有集群节点上,所以复制缓存的大小受节点上可用内存(RAM和磁盘)的数量限制。对于缓存读多写少且数据集较小的场景,此模式是理想的。如果业务系统确实在80%的时间内都在进行缓存查找,那么应该考虑使用REPLICATED缓存模式。
# 2.3.备份分区
Ignite默认会保存每个分区的单个副本(整个数据集的单个副本)。这时如果一个或多个节点故障,存储在这些节点上的分区将无法访问,为避免这种情况,Ignite可以配置为每个分区维护备份副本。
警告
备份默认是禁用的。
备份副本的配置是缓存(表)级的,如果配置2个备份副本,则集群将为每个分区维护3个副本。其中一个分区称为主分区,其他两个分区称为备份分区,主分区对应的节点称为该分区中存储的键的主节点,否则称为备份节点。
当某些键的主分区对应的节点离开集群时,Ignite会触发分区映射交换(PME)过程,PME会将键的某个备份分区(如果已配置)标记为主分区。
备份分区提高了数据的可用性,在某些情况下还会提高读操作的速度,因为如果本地节点可用,Ignite会从备份分区中读取数据(这是可以禁用的默认行为,具体请参见缓存配置章节)。但是备份也会增加内存消耗或持久化存储的大小(如果启用)。
提示
备份分区只能在PARTITIONED模式下配置,请参见配置分区备份章节。
# 2.4.分区映射交换
分区映射交换(PME)是共享整个集群分区分布(分区映射)的信息的过程,以便每个节点都知道在哪里寻找某个键。无论是应用户请求还是由于故障,每当缓存的分区分配发生更改时(例如新节点加入拓扑或旧节点离开拓扑)都需要PME。
包括但不限于会触发PME的事件:
- 一个新节点加入/离开拓扑;
- 新的缓存开始/停止;
- 创建索引。
当发生PME触发事件时,集群将等待所有正在进行的事务完成,然后启动PME。同样在PME期间,新事务将推迟直到该过程完成。
PME过程的工作方式是:协调器节点向所有节点请求其拥有的分区信息,然后每个节点将此信息反馈给协调器。协调器收到所有节点的消息后,会将所有信息合并为完整的分区映射,并将其发送给所有节点。当协调器接收了所有节点的确认消息后,PME过程就完成了。
# 2.5.再平衡
有关详细信息,请参见数据再平衡章节的内容。
# 2.6.分区丢失策略
在整个集群的生命周期中,由于某些拥有分区副本的主节点和备份节点的故障,一些数据分区可能丢失。这种情况会导致部分数据丢失,需要根据具体业务场景进行处理。有关分区丢失策略的详细信息,请参见分区丢失策略。
# 3.关联并置
在许多情况下,如果不同的条目经常一起访问,则将它们并置在一起就很有用,即在一个节点(存储对象的节点)上就可以执行多条目查询,这个概念称为关联并置。
关联函数将条目分配给分区,具有相同关联键的对象将进入相同的分区,这样就可以设计将相关条目存储在一起的数据模型,这里的“相关”是指处于父子关系的对象或经常一起查询的对象。
例如,假设有Person和Company对象,并且每个人都有一个companyId字段,该字段表示其所在的公司。通过将Person.companyId和Company.ID作为关联键,可以保证同一公司的所有人都存储在同一节点上,该节点也存储了公司对象,这样查询在某公司工作的人就可以在单个节点上处理。
还可以将计算任务与数据并置,具体请参见计算和数据并置。
# 3.1.配置关联键
如果未明确指定关联键,则将缓存键用作默认的关联键,如果使用SQL语句将缓存创建为SQL表,则PRIMARY KEY是默认的关联键。
如果要通过不同的字段并置来自两个缓存的数据,则必须使用复杂的对象作为键。该对象通常包含一个唯一地标识该缓存中的对象的字段,以及一个要用于并置的字段。
下面会介绍自定义键中配置自定义关联键的几种方法。
以下示例说明了如何使用自定义键类和@AffinityKeyMapped注解将人对象与公司对象并置:
也可以使用CacheKeyConfiguration类在缓存配置中配置关联键:
除了自定义键类,还可以使用AffinityKey类,其是专门为使用自定义关联映射设计的。
# 4.二进制编组器
# 4.1.基本概念
二进制对象是Ignite中表示数据序列化的组件,有如下优势:
- 它可以从对象的序列化形式中读取任意的属性,而不需要将该对象完整地反序列化,这个功能消除了将缓存的键和值类部署到服务端节点类路径的必要性;
- 它可以为同一个类型的对象增加和删除属性,给定的服务端节点不需要有模型类的定义,这个功能允许动态改变对象的结构,甚至允许多个客户端以共存的模式持有类定义的不同版本;
- 它可以根据类型名构造一个新的对象,不需要类定义,因此允许动态类型创建;
二进制对象只可以用于使用默认的二进制编组器时(即没有在配置中显式设置其它编组器)。
限制
BinaryObject格式实现也带来了若干个限制:
- 在内部Ignite不会写属性以及类型的名字,而是使用一个小写的名字哈希来标示一个属性或者类型,这意味着属性或者类型不能有同样的名字哈希。即使序列化不会在哈希冲突时立即生效,但Ignite在配置级别提供了一种方法来解决此冲突;
- 同样的原因,
BinaryObject格式在类的不同层次上也不允许有同样的属性名; - 如果类实现了
Externalizable接口,Ignite会使用OptimizedMarshaller,OptimizedMarshaller会使用writeExternal()和readExternal()来进行类对象的序列化和反序列化,这需要将实现Externalizable的类加入服务端节点的类路径中。
二进制对象的入口是IgniteBinary,可以从Ignite实例获得,包含了操作二进制对象的所有必要的方法。
自动化哈希值计算和Equals实现
BinaryObject格式实现隐含了一些限制:
如果对象可以被序列化到二进制形式,那么Ignite会在序列化期间计算它的哈希值并且将其写入最终的二进制数组。另外,Ignite还为二进制对象的比较提供了equals方法的自定义实现。这意味着不需要为在Ignite中使用自定义键和值覆写GetHashCode和Equals方法,除非它们无法序列化成二进制形式。比如,Externalizable类型的对象无法被序列化成二进制形式,这时就需要自行实现hashCode和equals方法,具体可以看上面的限制章节。
# 4.2.配置二进制对象
在绝大多数情况下不需要额外地配置二进制对象。
但是,如果需要覆写默认的类型和属性ID计算或者加入BinarySerializer,可以为IgniteConfiguration定义一个BinaryConfiguration对象,这个对象除了为每个类型指定映射以及序列化器之外还可以指定一个全局的名字映射、一个全局ID映射以及一个全局的二进制序列化器。对于每个类型的配置,通配符也是支持的,这时提供的配置会适用于匹配类型名称模板的所有类型。
<bean id="ignite.cfg" class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="binaryConfiguration">
<bean class="org.apache.ignite.configuration.BinaryConfiguration">
<property name="nameMapper" ref="globalNameMapper"/>
<property name="idMapper" ref="globalIdMapper"/>
<property name="typeConfigurations">
<list>
<bean class="org.apache.ignite.binary.BinaryTypeConfiguration">
<property name="typeName" value="org.apache.ignite.examples.*"/>
<property name="serializer" ref="exampleSerializer"/>
</bean>
</list>
</property>
</bean>
</property>
</bean>
# 4.3.BinaryObject API
Ignite默认使用反序列化值作为最常见的使用场景,要启用BinaryObject处理,需要获得一个IgniteCache的实例然后使用withKeepBinary()方法。启用之后,如果可能,这个标志就会确保从缓存返回的对象都是BinaryObject格式的。将值传递给EntryProcessor和CacheInterceptor也是同样的处理。
平台类型
注意当通过withKeepBinary()方法启用BinaryObject处理时并不是所有的对象都会表示为BinaryObject,会有一系列的平台类型,包括基本类型、String、UUID、Date、Timestamp、BigDecimal、Collections、Maps和这些类型的数组,它们不会被表示为BinaryObject。
注意在下面的示例中,键类型为Integer,它不会被修改,因为它是平台类型。
// Create a regular Person object and put it to the cache.
Person person = buildPerson(personId);
ignite.cache("myCache").put(personId, person);
// Get an instance of binary-enabled cache.
IgniteCache<Integer, BinaryObject> binaryCache = ignite.cache("myCache").withKeepBinary();
// Get the above person object in the BinaryObject format.
BinaryObject binaryPerson = binaryCache.get(personId);
# 4.4.使用BinaryObjectBuilder修改二进制对象
BinaryObject实例是不可变的,要更新属性或者创建新的BinaryObject,必须使用BinaryObjectBuilder的实例。
BinaryObjectBuilder的实例可以通过IgniteBinary入口获得。它可以使用类型名创建,这时返回的对象不包含任何属性,或者它也可以通过一个已有的BinaryObject创建,这时返回的对象会包含从该BinaryObject中拷贝的所有属性。
获取BinaryObjectBuilder实例的另外一个方式是调用已有BinaryObject实例的toBuilder()方法,这种方式创建的对象也会从BinaryObject中拷贝所有的数据。
限制
- 无法修改已有字段的类型;
- 无法变更枚举值的顺序,也无法在枚举值列表的开始或者中部添加新的常量,但是可以在列表的末尾添加新的常量。
下面是一个使用BinaryObjectAPI来处理服务端节点的数据而不需要将程序部署到服务端以及不需要实际的数据反序列化的示例:
// The EntryProcessor is to be executed for this key.
int key = 101;
cache.<Integer, BinaryObject>withKeepBinary().invoke(
key, new CacheEntryProcessor<Integer, BinaryObject, Object>() {
public Object process(MutableEntry<Integer, BinaryObject> entry,
Object... objects) throws EntryProcessorException {
// Create builder from the old value.
BinaryObjectBuilder bldr = entry.getValue().toBuilder();
//Update the field in the builder.
bldr.setField("name", "Ignite");
// Set new value to the entry.
entry.setValue(bldr.build());
return null;
}
});
# 4.5.BinaryObject类型元数据
如前所述,二进制对象结构可以在运行时进行修改,因此获取一个存储在缓存中的一个特定类型的信息也可能是有用的,比如属性名、属性类型名,关联属性名,Ignite通过BinaryType接口满足这样的需求。
这个接口还引入了一个属性getter的更快的版本,叫做BinaryField。这个概念类似于Java的反射,可以缓存BinaryField实例中读取的属性的特定信息,如果从一个很大的二进制对象集合中读取同一个属性就会很有用。
Collection<BinaryObject> persons = getPersons();
BinaryField salary = null;
double total = 0;
int cnt = 0;
for (BinaryObject person : persons) {
if (salary == null)
salary = person.type().field("salary");
total += salary.value(person);
cnt++;
}
double avg = total / cnt;
# 4.6.BinaryObject和CacheStore
在缓存API上调用withKeepBinary()方法对于将用户对象传入CacheStore的方式不起作用,这么做是故意的,因为大多数情况下单个CacheStore实现要么使用反序列化类,要么使用BinaryObject表示。要控制对象传入CacheStore的方式,需要使用CacheConfiguration的storeKeepBinary标志,当该标志设置为false时,会将反序列化值传入CacheStore,否则会使用BinaryObject表示。
下面是一个使用BinaryObject的CacheStore的伪代码示例:
public class CacheExampleBinaryStore extends CacheStoreAdapter<Integer, BinaryObject> {
@IgniteInstanceResource
private Ignite ignite;
/** {@inheritDoc} */
@Override public BinaryObject load(Integer key) {
IgniteBinary binary = ignite.binary();
List<?> rs = loadRow(key);
BinaryObjectBuilder bldr = binary.builder("Person");
for (int i = 0; i < rs.size(); i++)
bldr.setField(name(i), rs.get(i));
return bldr.build();
}
/** {@inheritDoc} */
@Override public void write(Cache.Entry<? extends Integer, ? extends BinaryObject> entry) {
BinaryObject obj = entry.getValue();
BinaryType type = obj.type();
Collection<String> fields = type.fieldNames();
List<Object> row = new ArrayList<>(fields.size());
for (String fieldName : fields)
row.add(obj.field(fieldName));
saveRow(entry.getKey(), row);
}
}
# 4.7.二进制Name映射器和二进制ID映射器
在内部,为了性能Ignite不会写属性或者类型名字的完整字符串,而是为类型和属性名写一个整型哈希值。经过测试,在类型相同时,属性名或者类型名的哈希值冲突实际上是不存在的,为了性能使用哈希值是安全的。对于当不同的类型或者属性确实冲突的场合,BinaryNameMapper和BinaryIdMapper可以为该类型或者属性名覆写自动生成的哈希值。
BinaryNameMapper:映射类型/类和属性名到不同的名字;
BinaryIdMapper:映射从BinaryNameMapper来的类型和属性名到ID,以便于Ignite内部使用。
Ignite直接支持如下的映射器实现:
BinaryBasicNameMapper:BinaryNameMapper的一个基本实现,对于一个给定的类,根据使用的setSimpleName(boolean useSimpleName)属性值,会返回一个完整或者简单的名字;BinaryBasicIdMapper:BinaryIdMapper的一个基本实现,它有一个lowerCase配置属性,如果属性设置为false,那么会返回一个给定类型或者属性名的哈希值,如果设置为true,会返回一个给定类型或者属性名的小写形式的哈希值。
如果仅仅使用Java或者.NET客户端并且在BinaryConfiguration中没有指定映射器,那么Ignite会使用BinaryBasicNameMapper并且simpleName属性会被设置为false,使用BinaryBasicIdMapper并且lowerCase属性会被设置为true。
如果使用了C++客户端并且在BinaryConfiguration中没有指定映射器,那么Ignite会使用BinaryBasicNameMapper并且simpleName属性会被设置为true,使用BinaryBasicIdMapper并且lowerCase属性会被设置为true。
如果使用Java、.Net或者C++,默认是不需要任何配置的,只有当需要平台协同、名字转换复杂的情况下,才需要配置映射器。
18624049226
