# 介绍
# 1.概述
Apache Ignite是一个兼容ANSI-99、水平可扩展以及容错的分布式SQL数据库,这个分布式是以数据在集群范围的复制或者分区的形式提供的,具体的形式取决于使用场景。
作为一个SQL数据库,Ignite支持所有的DML指令,包括SELECT、UPDATE、INSERT和DELETE,它还实现了一个与分布式系统有关的DDL指令的子集。
Ignite的一个突出特性是完全支持分布式的SQL关联,Ignite支持并置和非并置的数据关联。并置时,关联是在每个节点的可用数据集上执行的,而不需要在网络中移动大量的数据,这种方式在分布式数据库中提供了最好的扩展性和性能。
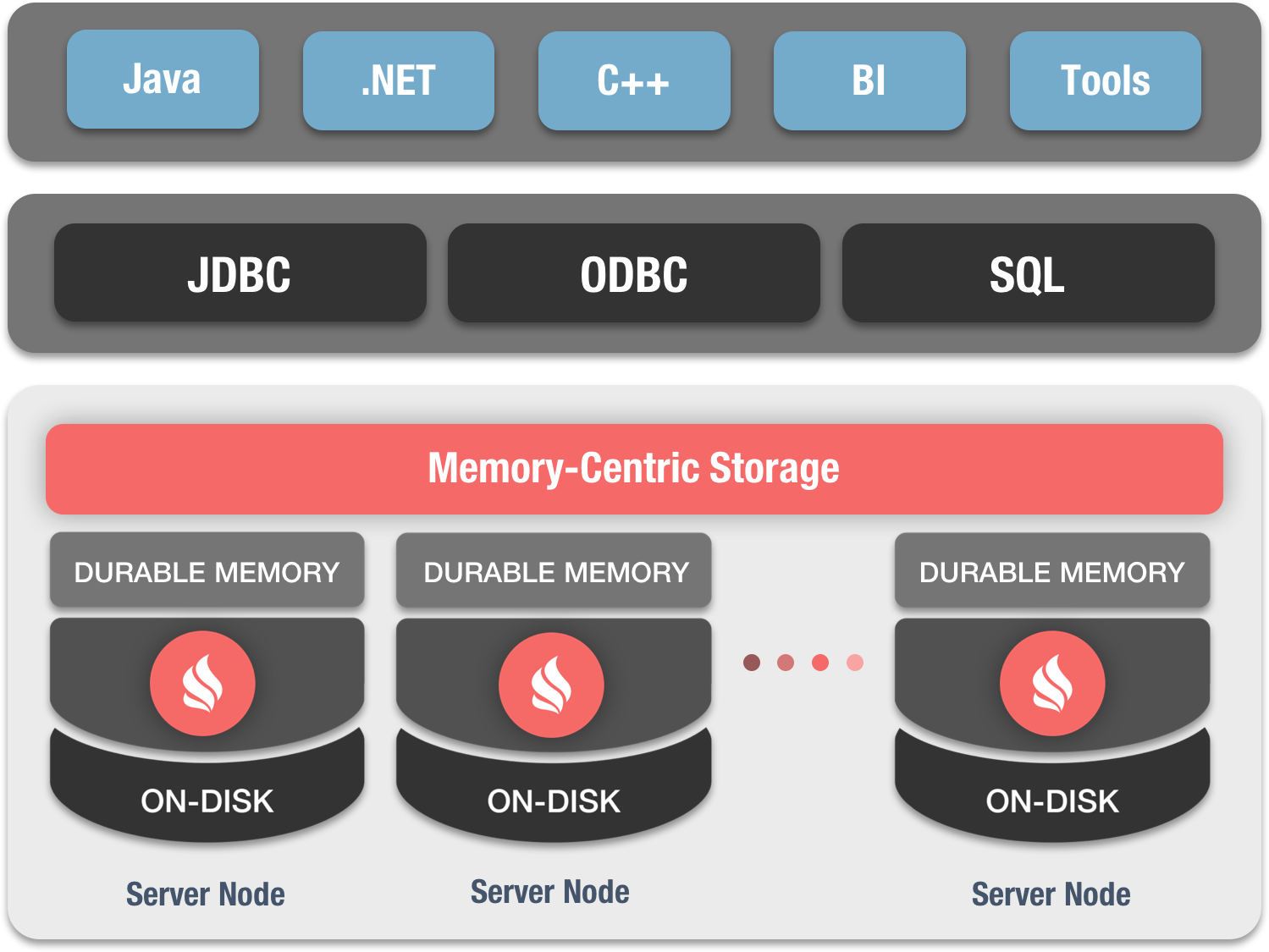
和很多的分布式SQL数据库不同,对于数据和索引,Ignite将内存和磁盘都视为完整有效的存储层,但是磁盘是可选的,如果禁用,Ignite就变为纯内存数据库。
可以像其它的SQL存储一样,根据需要与Ignite进行交互,比如通过外部的工具或者应用使用JDBC或者ODBC驱动进行连接。在这之上,Java、.NET和C++开发者也可以使用Ignite的原生SQL API。
# 2.入门
# 2.1.概述
Ignite支持数据定义语言(DDL)语句,可以在运行时创建和删除表和索引,还可以支持数据操作语言(DML)来执行查询,这些不管是Ignite的原生SQL API还是ODBC和JDBC驱动,都是支持的。
在下面的示例中,会使用一个包含两个表的模式,这些表会用于保存城市以及居住在那里的人的信息,假定一个城市有很多的人,并且人只会居住于一个城市,这是一个一对多(1:m)的关系。
# 2.2.SQL接入
作为入门来说,可以使用一个SQL工具,在后面的SQL工具章节中会有一个示例来演示如何配置SQL工具。还可以使用SQLLine接入集群然后在命令行执行SQL语句。
如果希望从源代码入手,下面的示例代码会演示如果通过JDBC以及ODBC驱动来获得一个连接:
JDBC连接会使用thin模式驱动然后接入本地主机(127.0.0.1),一定要确保ignite-core.jar位于应用或者工具的类路径中,具体信息可以查看JDBC驱动相关的章节。
ODBC连接也是接入本地localhost,端口是10800,具体可以查看ODBC驱动相关的文档。
不管选择哪种方式,都需要打开一个命令行工具,然后转到{apache-ignite-version}/bin,然后执行ignite.sh或者ignite.bat脚本,这样可以启动一个或者多个节点,如果使用了Ignite.NET或者Ignite.C++,那么也可以使用对应的可执行文件启动一个节点。
如果节点是通过Java应用启动,要保证在Maven的pom.xml文件中包含ignite-indexing模块依赖:
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-indexing</artifactId>
<version>${ignite.version}</version>
</dependency>
# 2.3.创建表
当前,创建的每个表都会位于PUBLIC模式,在模式和索引章节会有更详细的信息。
下面的示例代码会创建City和Person表:
CREATE TABLE命令执行之后,会做如下的工作:
- 会自动使用表名创建一个分布式缓存,它会用于存储City和Person类型的对象,这个缓存存储的City和Person对象可以与特定的Java、.NET和C++类或者二进制对象相对应;
- 会定义一个带有所有参数的SQL表;
- 数据以键-值记录的形式存储,主键列会用作存储对象的键,剩下的字段属于值,这就意味着可以使用键值API来处理数据。
和分布式缓存相关的参数是通过WITH子句传递的,如果忽略了WITH子句,那么缓存会使用CacheConfiguration对象的默认参数来创建。
在上面的示例中,对于Person表,Ignite创建了一个有一份备份数据的分布式缓存,city_id作为关联键,这些扩展参数是Ignite特有的,通过WITH进行传递,要为表配置其它的缓存参数,需要使用template参数,并且使用之前注册的缓存配置的名字(通过代码或者XML),具体可以参照扩展参数相关章节。
很多时候将不同的条目并置在一起非常有用,通常业务逻辑需要访问不止一个数据条目,将它们并置在一起会确保具有相同affinityKey的所有条目会被缓存在同一个节点上,这样就不需要从远程获取数据以避免耗时的网络开销。
在本示例中,有City和Person对象,并且希望并置Person对象及其居住的City对象,要做到这一点,就像上例所示,使用了WITH子句并且指定了affinityKey=city_id。
# 2.4.创建索引
定义索引可以加快查询的速度,下面是创建索引的示例:
# 2.5.插入数据
对数据进行查询之前,需要在两个表中加载部分数据,下面是如何往表中插入数据的示例:
# 2.6.查询数据
数据加载之后,就可以执行查询了。下面就是如何查询数据的示例,其中包括两个表之间的关联:
# 2.7.修改数据
有时数据是需要修改的,这时就可以执行修改操作来修改已有的数据,下面是如何修改数据的示例:
# 2.8.删除数据
可能还需要从数据库中删除数据,下面是删除数据的示例:
# 2.9.示例
GitHub上有和这个入门文档有关的完整代码。
18624049226

SQL参考 →