# Kafka Connect之在2.3版本中的改进
在Kafka的2.3版本中,对Kafka Connect做了很大的改进。首先就是在添加和删除连接器时,修改了Kafka Connect处理任务的方式。之前这个动作造成了整个系统的停顿,这是一直被开发和运维人员诟病的地方,除此之外,社区中频繁提到的其他一些问题,也得到了解决。
# Kafka Connect中的增量协作再平衡
Kafka Connect集群由一个或多个工作节点进程组成,集群以任务的形式分发连接器的负载。在添加或删除连接器或工作节点时,Kafka Connect会尝试再平衡这些任务。在Kafka的2.3版本之前,集群会停止所有任务,重新计算所有任务的执行位置,然后重启所有任务。每次再平衡都会暂停所有数据进出的工作,通常时间很短,但有时也会持续一段时间。
现在通过KIP-415,Kafka 2.3用增量协作再平衡做了替代,以后将仅对需要启动、停止或移动的任务进行再平衡。具体的详细信息请参见这里。
下面用一些连接器做了一个简单的测试,这里只使用了一个分布式Kafka Connect工作节点,而源端使用了kafka-connect-datagen,它以固定的时间间隔根据给定的模式生成随机数据。以固定的时间间隔就可以粗略地计算由于再平衡而停止任务的时间,因为生成的消息作为Kafka消息的一部分,包含了时间戳。这些消息之后会被流式注入Elasticsearch,之所以用它,不仅因为它是一个易于使用的接收端,也因为可以通过观察源端消息的时间戳来查看生产中的任何停顿。
通过如下的方式,可以创建源端:
curl -s -X PUT -H "Content-Type:application/json" http://localhost:8083/connectors/source-datagen-01/config \
-d '{
"connector.class": "io.confluent.kafka.connect.datagen.DatagenConnector",
"kafka.topic": "orders",
"quickstart":"orders",
"max.interval":200,
"iterations":10000000,
"tasks.max": "1"
}'
通过如下方式创建接收端:
curl -s -X PUT -H "Content-Type:application/json" \
http://localhost:8083/connectors/sink-elastic-orders-00/config \
-d '{
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"topics": "orders",
"connection.url": "http://elasticsearch:9200",
"type.name": "type.name=kafkaconnect",
"key.ignore": "true",
"schema.ignore": "false",
"transforms": "addTS",
"transforms.addTS.type": "org.apache.kafka.connect.transforms.InsertField$Value",
"transforms.addTS.timestamp.field": "op_ts"
}'
这里使用了单消息转换,将Kafka消息的时间戳提升到消息本身的字段中,以便可以在Elasticsearch中进行公开。之后会使用Kibana进行绘制,这样产生的消息数量下降就可以显示出来,与再平衡发生的位置一致:
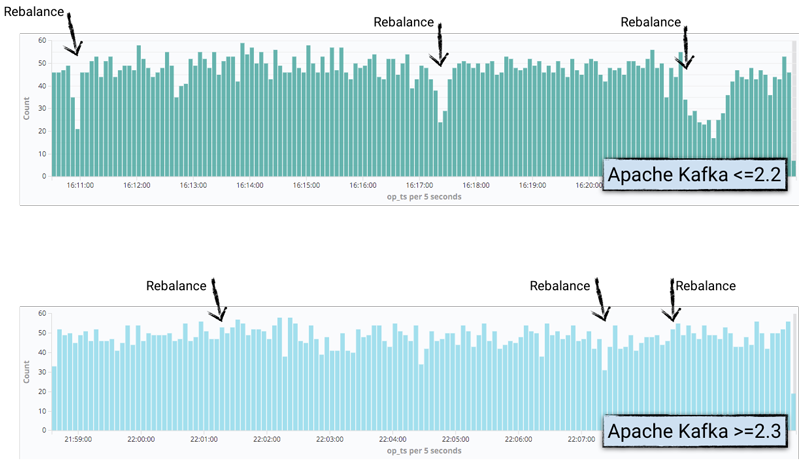
在Kafka Connect的工作节点日志中,可以查看活动和时间,并对Kafka的2.2版本和2.3版本的行为进行比较:
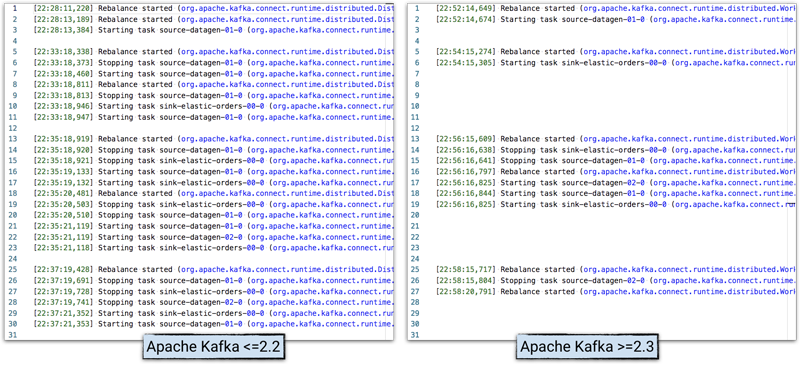
**注意:**为了清楚地说明问题,日志做了精简处理。
# 对日志的改进
在再平衡问题(如前述)已大大改善之后,Kafka Connect的第二大困扰可能是难以在Kafka Connect工作节点日志中确定某个消息属于哪个连接器。
之前可以直接从连接器的任务中获取日志中的消息,例如:
INFO Using multi thread/connection supporting pooling connection manager (io.searchbox.client.JestClientFactory)
INFO Using default GSON instance (io.searchbox.client.JestClientFactory)
INFO Node Discovery disabled... (io.searchbox.client.JestClientFactory)
INFO Idle connection reaping disabled... (io.searchbox.client.JestClientFactory)
他们属于哪个任务?不清楚。也许会认为JestClient与Elasticsearch有关,也许它们来自Elasticsearch连接器,但是现在有5个不同的Elasticsearch连接器在运行,那么它们来自哪个实例?更不用说连接器可以有多个任务了。
在Apache Kafka 2.3中,可以使用映射诊断上下文(MDC)日志,在日志中提供了更多的上下文信息:
INFO [sink-elastic-orders-00|task-0] Using multi thread/connection supporting pooling connection manager (io.searchbox.client.JestClientFactory:223)
INFO [sink-elastic-orders-00|task-0] Using default GSON instance (io.searchbox.client.JestClientFactory:69)
INFO [sink-elastic-orders-00|task-0] Node Discovery disabled... (io.searchbox.client.JestClientFactory:86)
INFO [sink-elastic-orders-00|task-0] Idle connection reaping disabled... (io.searchbox.client.JestClientFactory:98)
这个日志格式的更改默认是禁用的,以保持后向兼容性。要启用此改进,需要编辑etc/kafka/connect-log4j.properties文件,按照如下方式修改log4j.appender.stdout.layout.ConversionPattern:
log4j.appender.stdout.layout.ConversionPattern=[%d] %p %X{connector.context}%m (%c:%L)%n
通过环境变量CONNECT_LOG4J_APPENDER_STDOUT_LAYOUT_CONVERSIONPATTERN,Kafka Connect的Docker镜像也支持了这个特性。
具体细节请参见KIP-449。
REST改进
KIP-465为/connectorsREST端点添加了一些方便的功能。通过传递其他参数,可以获取有关每个连接器的更多信息,而不必迭代结果并进行其他REST调用。
例如,在Kafka 2.3之前要查询所有任务的状态,必须执行以下操作,使用xargs迭代输出并重复调用status端点:
$ curl -s "http://localhost:8083/connectors"| \
jq '.[]'| \
xargs -I{connector_name} curl -s "http://localhost:8083/connectors/"{connector_name}"/status"| \
jq -c -M '[.name,.connector.state,.tasks[].state]|join(":|:")'| \
column -s : -t| sed 's/\"//g'| sort
sink-elastic-orders-00 | RUNNING | RUNNING
source-datagen-01 | RUNNING | RUNNING
现在使用Kafka 2.3,可以使用/connectors?expand=status加上一些jq技巧进行单个REST调用,就可以达到和之前一样的效果:
$ curl -s "http://localhost:8083/connectors?expand=status" | \
jq 'to_entries[] | [.key, .value.status.connector.state,.value.status.tasks[].state]|join(":|:")' | \
column -s : -t| sed 's/\"//g'| sort
sink-elastic-orders-00 | RUNNING | RUNNING
source-datagen-01 | RUNNING | RUNNING
还有/connectors?expand=status,它将返回每个连接器信息,如配置、连接器类型等,也可以把它们结合起来:
$ curl -s "http://localhost:8083/connectors?expand=info&expand=status"|jq 'to_entries[] | [ .value.info.type, .key, .value.status.connector.state,.value.status.tasks[].state,.value.info.config."connector.class"]|join(":|:")' | \
column -s : -t| sed 's/\"//g'| sort
sink | sink-elastic-orders-00 | RUNNING | RUNNING | io.confluent.connect.elasticsearch.ElasticsearchSinkConnector
source | source-datagen-01 | RUNNING | RUNNING | io.confluent.kafka.connect.datagen.DatagenConnector
Kafka Connect现已支持client.id
因为KIP-411,Kafka Connect现在可以以更有用的方式为每项任务配置client.id。之前,只能看到consumer-25作为连接器的消费者组的一部分从给定的分区进行消费,现在则可以将其直接绑定回特定的任务,从而使故障排除和诊断更加容易。
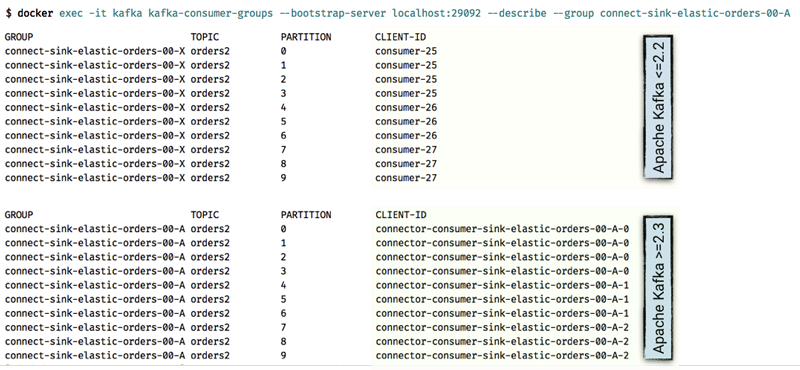
连接器级生产者/消费者配置覆写
长期以来的一个常见需求是能够覆写分别由Kafka Connect接收端和源端使用的消费者设置或生产者设置。到目前为止,它们都采用了工作节点配置中指定的值,除非生成了更多的工作节点,否则无法对诸如安全主体之类的内容进行细粒度的控制。
Kafka 2.3中的KIP-458使工作节点能够允许对配置进行覆写。connector.client.config.override.policy是一个新的参数,在工作节点级可以有3个可选项:
| 值 | 描述 |
|---|---|
| None | 默认策略,不允许任何配置的覆写 |
| Principal | 允许覆盖生产者、消费者和admin前缀的security.protocol、sasl.jaas.config和sasl.mechanism |
| All | 允许覆盖生产者、消费者和admin前缀的所有配置 |
通过在工作节点配置中设置上述参数,现在可以针对每个连接器对配置进行覆写。只需提供带有consumer.override(接收端)或producer.override(源端)前缀的必需参数即可,还可以针对死信队列使用admin.override。
在下面的示例中,创建连接器时,它将从主题的当前点开始消费数据,而不是读取主题中的所有可用数据,这是通过将consumer.override.auto.offset.reset配置为latest覆盖auto.offset.reset configuration来实现的。
curl -i -X PUT -H "Content-Type:application/json" \
http://localhost:8083/connectors/sink-elastic-orders-01-latest/config \
-d '{
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"topics": "orders",
"consumer.override.auto.offset.reset": "latest",
"tasks.max": 1,
"connection.url": "http://elasticsearch:9200", "type.name": "type.name=kafkaconnect",
"key.ignore": "true", "schema.ignore": "false",
"transforms": "renameTopic",
"transforms.renameTopic.type": "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.renameTopic.regex": "orders",
"transforms.renameTopic.replacement": "orders-latest"
}'
通过检查工作节点日志,可以看到覆写已经生效:
[2019-07-17 13:57:27,532] INFO [sink-elastic-orders-01-latest|task-0] ConsumerConfig values:
allow.auto.create.topics = true
auto.commit.interval.ms = 5000
auto.offset.reset = latest
[…]
可以看到这个ConsumerConfig日志条目与创建的连接器直接关联,证明了上述MDC日志记录的有用性。
第二个连接器运行于同一主题但没有consumer.override,因此继承了默认值earliest:
[2019-07-17 13:57:27,487] INFO [sink-elastic-orders-01-earliest|task-0] ConsumerConfig values:
allow.auto.create.topics = true
auto.commit.interval.ms = 5000
auto.offset.reset = earliest
[…]
通过将数据从主题流式传输到Elasticsearch可以检查配置的差异造成的影响。
$ curl -s "localhost:9200/_cat/indices?h=idx,docsCount"
orders-latest 2369
orders-earliest 144932
有两个索引:一个从同一主题注入了较少的消息,因为orders-latest索引只注入了连接器创建后才到达主题的消息;而另一个orders-earliest索引,由一个单独的连接器注入,它会使用Kafka Connect的默认配置,即会注入所有的新消息,再加上主题中原有的所有消息。
18624049226
